Версия для печати темы
Нажмите сюда для просмотра этой темы в обычном формате
Форум «Всё о Паскале» _ Задачи _ о динамических строковых массивах в Паскале
Автор: Carin 14.05.2007 21:12
Здравствуйте, господа!
Такая проблема возникла.
Задачка на поиск дублетов(пар слов, разнящихся между собой в одной букве) в считанном из файла словарике. Для того чтобы эти самые дублеты найти, необходимо, как я понимаю не раз погонять словарь. Соотвественно считать надо все это счастье в строковый массив. В условии оговорено, что размер словаря не должен превышать 25143 слова, каждое из которых не более 16 символов.
Вот тут и все проблемы начались. То, что я в статический массив не уложусь со своим словариком я поняла сразу  . Сделала динамический вариант обработки.
. Сделала динамический вариант обработки.
w_max = 16;{это максимальная длина слова}
label 1, 2;{метки для проверок}
type
str_char = string[w_max];{это для динамического строкового массива}
TDynArr = array[1..1] of str_char;
PDynArr = ^TDynArr;
var f: text;{файл со словарем и парами для поиска}
t_wd2: str_char;
n, i, j: word;
p_arr: PDynArr;{динамический строковый массив}
begin
assign(f, 'input.txt');
{сначала выясняем количество слов для получения динамического массива}
reset(f);
n:= 0;
while not eof(f) do
begin
readln(f, t_wd2);
if (n > n_max) or (length(t_wd2) = 0) then goto 1;
n:= n + 1;
end;
1: close(f);
reset(f);
{этот самый динамический строковый массив объявляем}
GetMem(p_arr, n * SizeOf(str_char));
{зачитываем слова в словарь}
writeln('Производится считывание словаря...');
i:= 1;
n:= 0;
while not eof(f) do
begin
readln(f, t_wd2);
if (n > n_max) or (length(t_wd2) = 0) then goto 2;
n:= n + 1;
p_arr^[n]:= t_wd2;
end;
2: writeln('Найдено ', n, ' слов в словаре');
close(f);
{чистим собственно массив}
FreeMem(p_arr, n * SizeOf(str_char));
Вот когда производится зачитывание всего словарика около 20 тыс слов разной длины, то выходит при попытке вывода на экран полученного массива, какая-то белиберда. То есть почему-то первые элементы массива оказываются затертыми последующими с повторами, с вкраплениями каких-то непечатных символов и т.д. Хотя при считываниии когда вывожу каждый новый считанный элемент для контроля - все правильно. Что это? Игры с памятью?
Могу приложить полный код и словарик при необходимости.
Автор: volvo 14.05.2007 21:18
...
GetMem(p_arr, n * SizeOf(str_char)); { <--- Здесь !!! }
...
Сколько памяти ты берешь? 20000 * 16 = 320000, а ведь можешь - только 65К... Тебе надо пойти еще дальше, и сделать не массив строк, а массив указателей на строки... Справишься, или помочь?
Автор: Carin 14.05.2007 21:28

Сколько памяти ты берешь? 20000 * 16 = 320000, а ведь можешь - только 65К...
Что меня смутило - не было run-time error насчет heap overflow. Почему? Просто перезаписываются начальные элементы.
Тебе надо пойти еще дальше, и сделать не массив строк, а массив указателей на строки... Справишься, или помочь?
Вот попробовала через линейный связный список, тут все четко - при переборе от 10 тыс. сразу идет сообщение об ошибке, но накладки нет.
label 2;
type
TWordStr = string[16];
PTItem = ^TItem;
TItem = record
Data: TWordStr;
next: PTItem;
end;
TWordList = record
first, last: PTItem;
end;
procedure InsertWord(var L: TWordList; s: string);
var p: PTItem;
begin
New(p);
p^.Data := s;
p^.next := nil;
if L.first = nil then L.first := p
else L.last^.next := p;
L.last := p
end;
var p, p2: PTItem;
L: TWordList;
f: text;
t_wd: TWordStr;
i: word;
begin
assign(f, 'input.txt');
reset(f);
i:= 0;
while not eof(f) do
begin
i:= i + 1;
if i > n_max then goto 2;
readln(f, t_wd);
InsertWord(L, t_wd);
end;
2: close(f);
{проверяем вывод, не покорежены ли элементы}
p:= L.first;
i:= 0;
while p <> nil do begin
i:= i + 1;
p2:= p;
while p2 <> nil do begin
WriteLn(p^.Data, '-', p2^.Data);
p2 := p2^.next;
end;
p := p^.next;
end;
readln;
end.
Но все-таки очень интересно, можно ли выкрутиться на все 100%
? Помощь насчет массива указателей на строки очень пригодилась бы, а то как-то пугают меня такие конструкции ....
Автор: volvo 14.05.2007 21:36
type
p_str = ^str_char; { <--- Вот этот указатель на строку }
str_char = string[w_max];{это для динамического строкового массива}
TDynArr = array[1 .. 1] of p_str;
PDynArr = ^TDynArr;
а теперь вместо:
{этот самый динамический строковый массив объявляем}
GetMem(p_arr, n * SizeOf(str_char));
{зачитываем слова в словарь}
делаем так (добавляем один шаг):
{этот самый динамический строковый массив объявляем}
GetMem(p_arr, n * SizeOf(p_str)); { <-- Взяли массив указателей }
For i := 1 to n do New(p_arr^[i]); { <--- выделяем, собственно, память под саму строку }
{зачитываем слова в словарь}
i:= 1;
n:= 0;
while not eof(f) do
begin
readln(f, t_wd2);
if (n > n_max) or (length(t_wd2) = 0) then goto 2;
n:= n + 1;
p_arr^[n]^:= t_wd2; { <--- Разыменование указателя }
end;
(набирал прямо здесь, но по-моему нигде не ошибся)
Если памяти по-прежнему не будет хватать - присоединяй программу и словарь полностью, будем искать еще и другие пути освобождения "кучи"...
Автор: Carin 14.05.2007 22:07
volvo, большое спасибо тебе за помочь, но! 8815 - вот предел при такой схеме. Зато перестали "сползать" элементы массива.
В принципе, я так думаю, это проблема самого Паскаля, ее не переплюнуть как таковую. Кстати, у меня компилятор - Turbo Pascal, не Borland - интересно, это может иметь значение ?
Ну вот, прога на всякий случай и словарик.
Прикрепленные файлы WORDS2.PAS ( 3.66 килобайт )
Кол-во скачиваний: 242
input.txt ( 185.07 килобайт )
Кол-во скачиваний: 4662
WORDS2.PAS ( 3.66 килобайт )
Кол-во скачиваний: 242
input.txt ( 185.07 килобайт )
Кол-во скачиваний: 4662
Автор: volvo 14.05.2007 22:11
Я посмотрел на словарик, и у меня созрело еще одно предложение - чтоб "съедалось" меньше памяти можно сделать "плавающий" размер строки, т.е. выделять именно столько памяти, сколько надо для хранения, а не всегда по 16 байт... Это сильно увеличит число читаемых слов...
Автор: Carin 14.05.2007 22:15
Я посмотрел на словарик, и у меня созрело еще одно предложение - чтоб "съедалось" меньше памяти можно сделать "плавающий" размер строки, т.е. выделять именно столько памяти, сколько надо для хранения, а не всегда по 16 байт... Это сильно увеличит число читаемых слов...
Это прекрасная мысль, но я не соображу как ее порешать. Вроде как размер string требует фиксированного размера? А объявлять через массив char каждое слово - брррр...
Автор: volvo 14.05.2007 23:25
Вот, посмотри чего я наваял... Программа заточена под TP, больше нигде работать не будет (я имею в виду современные компиляторы), но вроде читает все слова из словаря... И наложения никакого нет:
program FindLinks;
uses strings;
const
n_max = 12572; { _половина_ макс. количества слов }
w_max = 16; { Макс. длина слова }
type
p_str = ^str_char;
str_char = string[w_max];
{ Вот сердце этого извращения! объявляем 2 части массива !!! }
pvector = ^vector;
vector = array[1 .. n_max] of pointer;
TDynArr = array[0 .. 1] of pvector;
PDynArr = TDynArr;
label 1, 2;
var
f: text;
t_wd2, t_wd3: str_char;
n, i, j: word;
p_arr: PDynArr;
p_arr2, p_arr3: PDynArr;
n_par: word;
v_pair1, v_pair2: str_char;
p1: word;
vect_num: integer;
{ для добавления слова в словарь - пользоваться ТОЛЬКО вот этим: }
procedure put_dict(n: integer; const s: str_char);
var
line: integer;
begin
line := n div succ(n_max);
getmem(p_arr[line]^[(n mod succ(n_max)) + line], length(s) + 1);
move(s[0], p_arr[line]^[(n mod succ(n_max)) + line]^, length(s) + 1);
end;
{ для нахождения слова в словаре по его номеру - использовать эту функцию }
function get_dict(n: integer): str_char;
var
line: integer;
s: str_char;
len: byte;
begin
line := n div succ(n_max);
move(p_arr[line]^[(n mod succ(n_max)) + line]^, len, 1);
move(p_arr[line]^[(n mod succ(n_max)) + line]^, s[0], len + 1);
get_dict := s;
end;
begin
assign(f, 'input.txt');
reset(f);
new(p_arr[0]);
new(p_arr[1]);
writeln('reading dictionary ...');
i := 1;
n := 0;
while not eof(f) do begin
readln(f, t_wd2);
if (n > 2 * n_max) or (length(t_wd2) = 0) then goto 2;
n := n + 1;
write(n:6);
put_dict(n, t_wd2);
end;
2: writeln(n, ' words in dictionary ...');
writeln('duplicates...');
(* удалено на время проверки чтения в словарь *)
j := 2;
for i := 1 to n do
writeln (i, '-', get_dict(i), '-', get_dict(j));
dispose(p_arr[1]);
dispose(p_arr[0]);
readln;
end.

Автор: Carin 15.05.2007 0:19
Вот, посмотри чего я наваял... Программа заточена под TP, больше нигде работать не будет (я имею в виду современные компиляторы), но вроде читает все слова из словаря... И наложения никакого нет:
...
Гхм... У меня run-time error - heap overflow. Memory sizes вроде все выставила по максимуму. Странно. Что это может быть?

Автор: volvo 15.05.2007 1:00
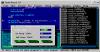
Как видишь, окно Output показывает что словарь прочтен и распечатан полностью... Кстати, сколько у тебя окон открыто в IDE Паскаля?
Эскизы прикрепленных изображений
Автор: Carin 15.05.2007 1:30
Без понятия... У меня вот такие настройки:
Как видишь, окно Output показывает что словарь прочтен и распечатан полностью... Кстати, сколько у тебя окон открыто в IDE Паскаля?
Мда.... Все вроде по умолчании... Окно одно и копия IDE одна... Загадка природы просто.... Нужно независимое тестирование, однако
....
Автор: volvo 15.05.2007 2:03
Попробуй выйти из IDE, и запустить без нее EXE-шник, если будет то же самое, я присоединю свой, проверишь его у себя... Что-то не в порядке, однако...
Автор: Carin 15.05.2007 2:11
Попробуй выйти из IDE, и запустить без нее EXE-шник, если будет то же самое, я присоединю свой, проверишь его у себя... Что-то не в порядке, однако...
Да, сделала exe - шку, тоже самое ошибка run-time. Давай свой exe.
Автор: volvo 15.05.2007 2:14
Попробуй...
Прикрепленные файлы __slovar.rar ( 4.75 килобайт )
Кол-во скачиваний: 184
__slovar.rar ( 4.75 килобайт )
Кол-во скачиваний: 184
Автор: Carin 15.05.2007 2:24
Попробуй...
Нда, не хочет.... Чем дальше, тем загадочней
... Чего ему может не хватать?
Автор: Lapp 15.05.2007 11:16
Я извиняюсь, что вторгаюсь в беседу
Но почему бы не брать просто массив по частям? Большими частями, по 64К. Тогда накладные расходы (на пойнтеры) будут минимальны (частей-то не больше десятка). Доступ можно организовать через две процедурки: положить и вынуть.
Вот, примерно так:
const
n_max=25143;
w_max=16;
type
tWord = string[w_max];
const
WordSize = SizeOf(tWord);
MaxPart = 10;
type
tPart = array[1..$FFF0 div WordSize]of tWord;
var
Dict:array[1..MaxPart]of ^tPart;
PartEnd:array[0..MaxPart]of LongInt;
i:word;
r,l:LongInt;
s:tWord;
function GetWord(j:LongInt):tWord;
var
i:word;
begin
i:=1;
while j>PartEnd[i] do Inc(i);
GetWord:=Dict[i]^[j-PartEnd[i-1]]
end;
procedure PutWord(j:LongInt;w:tWord);
var
i:word;
begin
i:=1;
while j>PartEnd[i] do Inc(i);
Dict[i]^[j-PartEnd[i-1]]:=w
end;
begin
Mark(p);
{Initialazing the array}
PartEnd[0]:=0;
r:=n_max;
i:=1;
while r>0 do begin
if MaxAvail>$FFF0 then l:=$FFF0 else l:=MaxAvail;
l:=l div WordSize;
if r<l then l:=r;
GetMem(Dict[i],l*WordSize);
Dec(r,l);
PartEnd[i]:=l+PartEnd[i-1];
WriteLn(i:5,PartEnd[i]:10);
Inc(i);
if (MaxAvail<WordSize)and(r>0) then begin
WriteLn('Could not get memory for ',r,' more words');
Exit
end
end;
{Working with the array}
repeat
Write('Type in a word: ');
ReadLn(s);
i:=Random(n_max)+1;
PutWord(i,s);
WriteLn('The word: ',GetWord(i),', - was stored at position ',i)
until s='';
Release(p)
end.
Автор: volvo 15.05.2007 13:17
Если тот вариант не отработал (хотя вот ЭТО непонятно, почему на одном компьютере оно работает, а на другом - нет), то практически гарантированно, что и предыдущий пост поведет себя так же...
Автор: Carin 16.05.2007 6:02
Lapp, раз Вы заинтересовались данной темой, то не могли бы Вы любезно поучаствовать в исследовании этого загадочного феномена? volvo пристегнул готовую exe-шку, у него она полностью рабочая, у меня сразу дает ошибку выполнения. Интересно. что получится на других машинах. А то как-то даже раздражает такое непоследовательное поведение проекта .
Автор: ramzes 16.05.2007 7:07
А "protected mode" можно использовать?
Автор: Lapp 16.05.2007 9:33
А то как-то даже раздражает такое непоследовательное поведение проекта
.Раздражение - вешь хорошая, если вынуждает к действию. В противном случае лучше раздражать центр удовольствия..
Насколько я понял, экзешник и сорс ведут себя одинаково. Значит, я бы обратился к сорсу. Пройтись по нему дебаггером (или просто наставить промежуточных печатей) и локализовать ошибку. Далее, посмотреть, как она происходит. Я понимаю, что это слишком общие рекомендации, но именно так следует действовать, если ничто другое не помогает.
Что касается меня, то код volvo у меня отработал, как положено
. Кстати, volvo, я извиняюсь за в некотором роде "дублирование" метода. Я хотел продемонстрировать некий общий подход, который годится для всяких массивов и совершенно не зависит от конкретики данных, давая максимальный выигрыш в памяти. При этом - каюсь - я не очень вник в программу volvo, обратил внимание только на некоторые отличия.. Сейчас я посмотрю поподробнее..Кстати, carin, а все же как мой код работает у тебя?..
Автор: volvo 16.05.2007 14:13
Carin, добавь в мой исходник распечатку номера прочитанного слова, чтобы хотя бы примерно знать, когда возникает ошибка... Можно еще добавить распечатку MemAvail после каждого GetMem, чтобы с этой стороны тоже исключить все возможные ошибки... И, если можно, немного о компьютере, на котором это запускается - какая там ОС, в частности? Я проверил программу еще на 2-х компьютерах - все работает...