Версия для печати темы
Нажмите сюда для просмотра этой темы в обычном формате
Форум «Всё о Паскале» _ Ада и другие языки _ Иерархическая кластеризация.
Автор: Andrewshkovskii 24.11.2009 21:59
Вершины – объекты
минимального остовного дерева группируются в кластеры.
Выбираются два объекта, которым соответствует минимальное ребро minjdj,
где j=1, n-1. Далее эти объекты стягиваются в один кластер (класс, таксон, страту) и
процедура шага 2 повторяется до тех пор, пока на n-1 этапе группирования не будет
сформирован один кластер, объединяющий все объекты. STOP.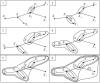
На рис. представлена последовательность группировки объектов в
кластеры для заданного на рис.1 примера минимального остовного дерева.
Порядок объединения объектов в кластеры отображён на рёбрах, которые
связывают объединяемые объекты .Таким образом, первыми
объединяются объекты X4 и Х5,которые в МОД связывает минимальное ребро d4
с весом 2. Вторыми объединяются объекты X2и X3, связанные ребром d2
с весом 3 , и так далее, пока на шестом этапе группирования ранее связанные объекты (X1,X2,X3,X4,X5,X6)
не будут объединены с объектом X7 ребром с весом 7.
И так , перейдем к описанию алгоритма кластеризации на примере :
Ребра МОД :
1. Е--2328-->Ом
2. В--2732-->И
3. Е--4667-->П
4. Л--5161-->Ом
5. О--6588-->И
7. П--14946-->В
И образуемые кластера :
(Шаг. №кластера)
1. 1.Е + ОМ значение кластера 2328
2. 1.
2. В + И 2732
3. 1. кластер поглощает вершину П, новый кластер Е+Ом+П 4667
2.
4. 1. поглощает вершину Л, новый кластер Е+Ом+П+Л 5161
2.
5. 1.
2. поглощает вершину О, новый кластер В + И + О 6588
6. 1 поглошает 2 и получается Л+Е+О+П+В+И+Ом 14946
Надеюсь понятно..вот как я понял этот алгоритм вербально :
Цикл от i=0 до n-1
Цикл от j=0 до n-1
Если множество вершин ребра/кластераi при пересечении с множеством вершин ребра/кластераj образует не пустое множество
если значение ребра/кластераj >=значению ребра/кластераi
ТОГДА образуется кластер соединением множества вершин ребра/кластераj и множества вершин ребра/кластераi
ИНАЧЕ наше ребро и есть кластер.
Правильно ли я понял алгоритм?
Вот так его можно описать в коде..
//ribs это объект класса реализующего :
// QSet<int> - множество вершин ребра/кластера, возвращается путем вызова метода items()
// свойство value, которое возвращает вес ребра/кластера
//считать, что операции &, &= - пересечение
// += - слияние.
for(int i=0;i<ribs.size();++i)
for(int j=0;j<ribs.size();++j)
if (ribs.at(j)!=ribs.at(i))//не сравниваем сами с собой..
if ( (!(ribs.at(i)->items() & ribs.at(j)->items()).empty()))
//если пересечение не образует пустое множество
if (ribs.at(j)->value() >= ribs.at(i)->value())
//если значение j ребра/кластера меньше i
{
ribs.at(j)->items()+=ribs.at(i)->items();//соединяем j и i ребро/кластера
}
else
{
// ребро и есть кластер
}
Автор: volvo 24.11.2009 22:15
Можно уточнить, в результате ты что хочешь получить? Так или иначе по окончании работы алгоритма ВСЕ вершины будут принадлежать к одному кластеру. В чем смысл этого всего? Тебе нужно хранить список кластеров с вершинами, входящими в них что-ли?
Автор: Andrewshkovskii 24.11.2009 22:34
http://el-niko.ru/lab/1/
Вот тут пример , это программа моего согруппника,только у него алгоритм не основан на ребрах. В результате для каждого среза (срез в данном случае - уникальное значение в МОД) на сайте он изображен снизу слева и справа, слева ввиде дендрограммы, справа в виде спика кластеров..Надо получить правильную дендрограмму, т.е все возможные кластера.
Вообще хотелось бы это дело опитимизировать так, что бы проходил наименьшее кол-во шагов. На каждом шаге формируется кластер, его необходимо отправлять во в такой вектор
vector < map < int, vector < cluster * > > ;
Т.е вектор срезов дендрограммы, где int - значение среза, vector <cluster *> вектор кластеров сформированных на данном срезе.
Автор: volvo 25.11.2009 0:46
Шо-то мне не очень понятно, что там твой согруппник сделал... Нет, ну сначала все идет как надо, а потом начинается нечто, не поддающееся объяснению. Смотри, чего я тут наваял (за основу взята твоя же программа для нахождения МОД):
#include <iostream>
#include <vector>
#include <limits>
bool exists(std::vector<int> vec, int value)
{
std::vector<int>::const_iterator it = std::find(vec.begin(), vec.end(), value);
return (it != vec.end()) ? true : false;
}
int main()
{
const int matrixSize = 8; // 17; // 6;
const std::string titles[matrixSize] =
{
"Lantasovo", "Egorshino", "Orehovo", "Perm",
"Voynovka", "Inskaya", "Omsk", "Ekaterinburg"
};
int dm[matrixSize][matrixSize] =
{
{ 0, 177, 171, 642, 981, 15, 403, 1315 },
{ 177, 0, 348, 465, 804, 192, 226, 1138 },
{ 171, 348, 0, 813, 1152, 156, 574, 1486 },
{ 642, 465, 813, 0, 339, 657, 239, 673 },
{ 981, 804, 1152, 339, 0, 996, 578, 334 },
{ 15, 192, 156, 657, 996, 0, 418, 1330 },
{ 403, 226, 574, 239, 578, 418, 0, 912 },
{ 1315, 1138, 1486, 673, 334, 1330, 912, 0 }
}; // матрица смежности графа
int sm[matrixSize][matrixSize];//матрица МОД
int used[matrixSize];//использованные вершины
int count=0;
int min;
for (int i=0; i< matrixSize; ++i)
{
used[i]=0;
for(int j=0;j< matrixSize;++j) sm[i][j]=0;
}
used[0]=1;
int idx;
do
{
min=std::numeric_limits<int>::max();
for(int i=0;i<matrixSize;++i)
{
if (used[i]!=0)
{
for(int j=0;j<matrixSize;++j)
if ( (dm[j][i] < min) && (dm[j][i]!=0) && (used[j]==0))
{
min=dm[j][i]; idx = j;
}
}
}
for(int i=0;i < matrixSize;++i)
for(int j=0;j<matrixSize;++j)
if( (dm[j][i]== min) && (used[j]==0) &&(used[i]==1))
{
used[j] =1;
sm[j][i]= sm[i][j] = min;
count++;
i=matrixSize;
break;
}
}
while(count < matrixSize-1);
// Выводим матрицу МОД ...
for(int i = 0; i < matrixSize; i++)
{
for(int j = 0; j < matrixSize; j++)
{
std::cout << sm[i][j] << " ";
}
std::cout << std::endl;
}
std::vector< std::pair<std::string, int> > tree;
std::vector<int> used_vertex;
for(int cycle = 0; cycle < matrixSize; cycle++)
{
std::pair<int, int> curr;
min = (cycle) ? std::numeric_limits<int>::max() : 0;
for(int i = 0; i < matrixSize; i++)
{
for(int j = i + 1; j < matrixSize; j++)
{
if(sm[i][j] > 0 && sm[i][j] < min && cycle &&
(exists(used_vertex, i) || exists(used_vertex, j)))
{
min = sm[i][j]; curr.first = i; curr.second = j;
}
}
}
//
if(!exists(used_vertex, curr.first))
{
used_vertex.push_back(curr.first);
tree.push_back(std::pair<std::string, int>(titles[curr.first], min));
sm[curr.first][curr.second] = sm[curr.second][curr.first] = 0;
}
else
if(!exists(used_vertex, curr.second))
{
used_vertex.push_back(curr.second);
tree.push_back(std::pair<std::string, int>(titles[curr.second], min));
sm[curr.first][curr.second] = sm[curr.second][curr.first] = 0;
}
}
std::vector< std::pair<std::string, int> >::iterator it;
for(it = tree.begin(); it != tree.end(); it++)
{
std::cout << it->first << " : " << it->second << std::endl;
}
return 0;
}
 (С++ так С++, по-полной)
(С++ так С++, по-полной)Данные - оттуда же, из таблицы по ссылке, при "Количество записей = 8". Вот вывод программы (исключая МОД, оно строится правильно):
Lantasovo : 0
Inskaya : 15
Orehovo : 156
Egorshino : 177
Omsk : 226
Perm : 239
Voynovka : 339
Ekaterinburg : 334
Чувствуешь? А у него каким-то необъяснимым образом сначала группируются Войновка с Екатеринбургом, и только потом этот кластер объединяется с остальными. Это откуда такое взялось?
Автор: Andrewshkovskii 25.11.2009 3:48
Что-то ты нагромоздил кода, хотя просто я использую QtStl в своем проекте, там попроще с векторами и множествами, да и для представления ребер/кластеров я реализовал отдельный класс( просто выкладывать его сюда мало смысла - всеравно без Qt не получиться скомпилировать)
А твой ответ не совсем ясен( честно скажу, в код не вникал).
У него на Срезе 15 обременяются вершины Инская и лянгасово, т.к между ними мин. ребро
на срезе 156 к этому ребру/кластеру добовляется вершина Орехово, т.к она связана с одной из вершин в предыдущем кластере(а именно - Инская) следующим мин. ребром с весом в 156..По тому же принципу и Егоршино на срезе 176 добавляется в тот же кластер, далее Омск на срезе 226, Пермь на срезе 239 (т.к все они имею связи через ребра МОД). На 334 срезе связывается Войновка и Екатеринбург, т.к они имею следующее мин. ребро из не использованных, и ни одна из этим вершин не имеется в предыдущих кластерах, поэтому они стают особняком на этом срезе, а после чего у них соединение на Перьми появляется и они объединяются в кластер..
А твои результаты я не понял. Может я плохо объясняю? Пожалуйста, спроси, что именно не понятно - я постараюсь объяснить более человеческим языком. Если надо, скину свои исходники.
Приведу всетаки полный код, может что яснее странет..
Сначала класс кластер/ребро :
интерфейс :
#ifndef CLUSTER_H
#define CLUSTER_H
#include <QSet>// Qt'вые множества
#include <QString>
class Cluster
{
private :
int value_;
QSet<int> items_;
public :
Cluster();
Cluster(Cluster & other);//конструктор копироавния
Cluster(int item1 ,int item2, int nValue);//для ребра конструктор
Cluster(int item1, int nValue);//для одной вершины
const int& value()const {return value_; }//возвращает вес кластера/ребра
void setValue(const int &newValue){value_=newValue;};//устанавливает вес
QSet<int> &items();//возврашает вершины в кластере/ребре
void append(Cluster * nClust);//"поглотить" другое ребро/кластер
QString toString(QStringList * lst);//перевести номера вершин в их строковой эквивалент
};
#endif // CLUSTER_H
Реализация ... :
#include "cluster.h"
Cluster::Cluster()
{
}
Cluster::Cluster(Cluster &other)
{
items_=other.items();
value_=other.value();
centerPos_=other.centerPos();
isPainted_=other.isPainted();
}
Cluster::Cluster(int item1 , int item2, int nValue)
{
value_=nValue;
items_.insert(item1);
items_.insert(item2);
}
Cluster::Cluster(int item1 , int nValue)
{
value_=nValue;
items_.insert(item1);
}
void Cluster::append(Cluster * nClust)
{
QSetIterator <int> it (nClust->items());
while (it.hasNext())//Java-style итератор, очень удобно. Пока есть элементы в контейнере
items_ << it.next();//забираем их из другого кластера.
}
QSet<int>& Cluster::items()
{
return items_;
}
QString Cluster::toString(QStringList * lst)
{
QString str;
QStringList * list = lst;
QSetIterator <int> it (items_);
str.append("|");
while(it.hasNext())
str.append(list->at(it.next())+" ");
str.append("|");
return str;
}
А вот алгоритм кластеризации :
void Model::calculateNewClustersModel(QStandardItemModel * spanningMatrixModel)
{
clusters.clear();//очищаем вектор срезов. Представляет из себя QVector <QMap < int, QVector <Cluster* > >
static bool *isNum = new bool;
int rc = spanningMatrixModel->rowCount();//размер МОД
int sM[rc][rc];//цисленный массив
QVector <Cluster *> ribs;//вектор ребер..
for (int i=0;i<rc;++i)
for (int j=0;j<rc;++j)
sM[i][j]=spanningMatrixModel->item(i,j)->text().toInt(isNum,10);
//перегоняет модель таблицы в численный массив
for (int i=0;i<rc;++i)
for (int j=i+1;j<rc;++j)
if (sM[i][j]!=0)
ribs.push_back(new Cluster(i,j,sM[i][j]));//собираем ребра
qSort(ribs.begin(),ribs.end(),cmp);//сортируем их по возрастанию веса.
for(int i=0;i<ribs.size();++i)
for(int j=0;j<ribs.size();++j)
if (ribs.at(j)!=ribs.at(i))//не сравниваем сами с собой
if ( (!(ribs.at(i)->items() & ribs.at(j)->items()).empty()))
//если на пересечении не пустое множество
if (ribs.at(j)->value() >= ribs.at(i)->value())
//и если ребро j имеет значение более ребра i
{
ribs.at(j)->items()+=ribs.at(i)->items();//поглатить ребро i
qDebug() << "appended" <<ribs.at(j)->toString(&vHeaderData) << ribs.at(j)->value();
//Вывод информации о том, какой кластер поглатился и кем
}
else
{
qDebug() <<"single" <<ribs.at(i)->toString(&vHeaderData) << ribs.at(i)->value();
//Вывод информации о том, какое ребро является уже кластером
}
for(int i=0;i<ribs.size();++i)
qDebug() << "2 " <<ribs.at(i)->toString(&vHeaderData) << ribs.at(i)->value() <<
" SIZE " << ribs.at(i)->items().size();
}
И вот вывод моего кода для "Вагонооборот" при 19 строках :
"|Войновка Бердяуш |" 416 SIZE 2
"|Алтайская Орехово |" 428 SIZE 2
"|Пермь Нижний Новгород |" 461 SIZE 2
"|Екатеринбург Челябинск |" 576 SIZE 2
"|Войновка Бердяуш Богданович |" 593 SIZE 3
"|Смычка Агрыз |" 799 SIZE 2
"|Алтайская Орехово Каменск-Уральский |" 1264 SIZE 3
"|Пермь Екатеринбург Нижний Новгород Челябинск |" 1305 SIZE 4
"|Алтайская Орехово Смычка Агрыз Каменск-Уральский |" 1453 SIZE 5
"|Курган Инская Юдино |" 2296 SIZE 3
"|Егоршино Пермь Екатеринбург Нижний Новгород Челябинск |" 2325 SIZE 5
"|Егоршино Пермь Омск Екатеринбург Нижний Новгород Челябинск |" 2328 SIZE 6
"|Курган Войновка Инская Бердяуш Юдино Богданович |" 2732 SIZE 6
"|Курган Алтайская Орехово Войновка Инская Бердяуш Смычка Агрыз Юдино Богданович Каменск-Уральский |" 2876 SIZE 11
"|Лянгасово Егоршино Пермь Омск Екатеринбург Нижний Новгород Челябинск |" 5161 SIZE 7
"|Курган Алтайская Орехово Войновка Инская Бердяуш Смычка Чусовская Агрыз Юдино Богданович Каменск-Уральский |" 5953 SIZE 12
"|Лянгасово Егоршино Орехово Пермь Войновка Инская Омск Екатеринбург Бердяуш Смычка Чусовская Агрыз Нижний Новгород Юдино Челябинск Богданович Каменск-Уральский Курган Алтайская |" 7984 SIZE 19
Что это значит?а вот что : SIZE - размер сформированного кластера, чилос перед SIZE - срез, на котором кластер сформирован, ну и соответственно его состав.
Мой вопрос в том, что можно это как-либо оптимизировать?Допустим, что бы не проходил вершины, которые уже посчитал как еденичный кластер и т.д. Просто для параметра "Количество сортировочных путей" у меня считает не правильно кластера т.к там одинаковые ребра по весу..
Да к тому же , эта оптимизация мне нужная для того, что бы нормально отрисовывать дендрограмму ( как на сайте снизу), т.к я буду использовать "события" Qt(сигналы/слоты) что, кого поглотило и отрисовывать их по-порядку, а не после нахождения...
Автор: volvo 25.11.2009 4:38
на срезе 156 к этому ребру/кластеру добовляется вершина Орехово, т.к она связана с одной из вершин в предыдущем кластере(а именно - Инская) следующим мин. ребром с весом в 156..По тому же принципу и Егоршино на срезе 176 добавляется в тот же кластер, далее Омск на срезе 226, Пермь на срезе 239 (т.к все они имею связи через ребра МОД).
Lantasovo : 0
Inskaya : 15
Orehovo : 156
Egorshino : 177
Omsk : 226
Perm : 239
Добавлено через 7 мин.
Автор: Andrewshkovskii 25.11.2009 4:52
На 0 этапе добавил Лянгасово куда-то?Ну про код просто я сморозил глупость, надо поспать...
А ебург с войновкой соединяется потому что между ними ребром со следующим мин. весом, а потом к Ебургу и Войновке остальные кластера.. Смотри, вот ребра :
"|Орехово Инская |" 156
"|Лянгасово Егоршино |" 177
"|Егоршино Омск |" 226
"|Пермь Омск |" 239
"|Войновка Екатеринбург |" 334
"|Пермь Войновка |" 339
Войновка соедененна с Екатеренбургом по 334 весу.
После чего, ищем с каким кластером у нас есть пересечение Войновка и Екатеринбург , и находим его в 339 значении.. а т.к в вершине ПЕРМЬ давно у нас уже остальные вершины собраны..то получается поглащение..
Ну если Qt есть, то вот проект (4.5.2 версия)
http://webfile.ru/4109074
Автор: volvo 25.11.2009 17:04
Так... До Qt я вчера так и не добрался, сегодня вечером гляну... Вот чего придумалось обычным STL-ем: main.cpp ( 5.01 килобайт )
Кол-во скачиваний: 719
main.cpp ( 5.01 килобайт )
Кол-во скачиваний: 719
(файл в кодировке Unicode)
Вот вывод:Lantasovo Inskaya SREZ = 15
Lantasovo Inskaya Orehovo SREZ = 156
Lantasovo Inskaya Egorshino SREZ = 177
Lantasovo Inskaya Egorshino Omsk SREZ = 226
Lantasovo Inskaya Egorshino Omsk Perm SREZ = 239
Voynovka Ekaterinburg SREZ = 334
Lantasovo Inskaya Egorshino Omsk Perm Voynovka Ekaterinburg SREZ = 339
Так более понятно, чем было раньше? Причем в каждый момент времени (при push_back-е) уже известно, что на данном шаге сделано, либо новый кластер, либо присоединение вершины к кластеру, либо слияние двух кластеров... Какой ты там пример говорил у тебя не получается? Надо будет попробовать на нем прогнать этот алгоритм.
Автор: Andrewshkovskii 25.11.2009 17:18
Да, результат более понятно,сейчас в коде по-разбираюсь.
Пример не получался с таких исходных данных :
0,2,6,5,3,6
2,0,4,3,1,4
6,4,0,1,3,0
5,3,1,0,2,1
3,1,3,2,0,3
6,4,0,1,3,0
Сейчас попробую прогнать.
Автор: Andrewshkovskii 25.11.2009 18:41
2 0 0 0 1 0
0 0 0 1 0 0
0 0 1 0 2 1
0 1 0 2 0 0
0 0 0 1 0 0
5
Egorshino Voynovka SREZ = 1
Orehovo Perm SREZ = 1
Orehovo Perm Inskaya SREZ = 1
Egorshino Voynovka Lantasovo SREZ = 2
Orehovo Perm Egorshino Voynovka SREZ = 2
Вот такой вот результат,из-за одинковых значений получается не правильно. Там, ещё, кстати, надо сравнивать на равенство, и равные по весу ребра/кластера тоже стаскивать.
Вот результат по моему коду :
Ребра
"|Егоршино Войновка |" 1
"|Орехово Пермь |" 1
"|Пермь Инская |" 1
"|Пермь Войновка |" 2
"|Лянгасово Егоршино |" 2
//appended - какое ребро/кластер образовано от поглащения
//single - ребро, которое и так есть кластер. В 5 сообщении видно когда эта информация выводиться..
appended "|Егоршино Пермь Войновка |" 2
appended "|Лянгасово Егоршино Войновка |" 2
appended "|Орехово Пермь Инская |" 1
appended "|Егоршино Орехово Пермь Войновка |" 2
appended "|Орехово Пермь Инская |" 1
appended "|Егоршино Орехово Пермь Войновка Инская |" 2
single "|Егоршино Орехово Пермь Войновка Инская |" 2
single "|Егоршино Орехово Пермь Войновка Инская |" 2
single "|Егоршино Орехово Пермь Войновка Инская |" 2
appended "|Лянгасово Егоршино Орехово Пермь Войновка Инская |" 2
single "|Лянгасово Егоршино Орехово Пермь Войновка Инская |" 2
single "|Лянгасово Егоршино Орехово Пермь Войновка Инская |" 2
single "|Лянгасово Егоршино Орехово Пермь Войновка Инская |" 2
appended "|Лянгасово Егоршино Орехово Пермь Войновка Инская |" 2
//результирующие ребра...
2 "|Егоршино Войновка |" 1 SIZE 2
2 "|Орехово Пермь Инская |" 1 SIZE 3
2 "|Орехово Пермь Инская |" 1 SIZE 3
2 "|Лянгасово Егоршино Орехово Пермь Войновка Инская |" 2 SIZE 6
2 "|Лянгасово Егоршино Орехово Пермь Войновка Инская |" 2 SIZE 6
Т.е. 2 раза одно и тоже ребро получается...
Автор: volvo 26.11.2009 5:44
В общем, вот чего у меня получилось после полной переработки всего, что только можно было проверить и сделать:  main.cpp ( 13.96 килобайт )
Кол-во скачиваний: 693
main.cpp ( 13.96 килобайт )
Кол-во скачиваний: 693
(все тот же Unicode, там каждый чих логгируется, если не хочешь - закомментируй #define TEST, тебе сразу вывалит результаты). По-моему все правильно делается, проверь еще на всякий случай, у меня что-то уже аллергия на эту программу образовалась 
Автор: Andrewshkovskii 26.11.2009 6:42
Мда, мне далекова-то до твоих мозгов, Владимир..Спасибо..
Считает, вроде бы, правильно. Ты не смотрел моё кутёвый пример?Просто может там используя qtstl не будет необходимости писать свои операторы пересечения и т.д..
А в коде попробую разобраться, ты не против, если я буду спрашивать?И ещё хотелось бы почитать вербальное(словестное) описание алгоритма, который ты придумал, может я тогда и сам дойду до того, что бы написать используя qtstl.
Почему так много Qt? Ну не знаю, просто нравиться она мне, и её stl шикарный.. А вот что касается std::stl, то тут меня пробелы в знаниях, и немного тяжеловато..
Автор: volvo 26.11.2009 6:59
На самом деле алгоритм очень простой:
С самого начала все вершины превращаем в кластеры, состоящие из одной-единственной вершины.
Потом проходим по таблице МОД-а и для каждой вершины запихиваем в вектор Edges все вершины/стоимости, с которыми связана данная вершина.
А потом просто проходим по всем кластерам, ищем в активных минимальное ребро. Нашли? Проверили, что связано это ребро тоже с активным кластером со второй стороны (вот на этом я потерял достаточно много времени, никак не мог сообразить, чего же не хватает)? Прекрасно, сливаем два кластера, для этого обновляем VX - список вершин, принадлежащих кластеру, и список Edges изменяем так, что все ссылки "друг на друга" просто убираются, остаются только ссылки на другие вершины, не принадлежащие в текущие момент данному кластеру.
А вот потом делается то, что отняло у меня еще больше времени, чем проверка активности второго кластера. Вот этот кусок необходим перед тем, как задизейблить кластер, влитый в другой:
// ***Я раньше не делал этого, у меня получался сплошной бред в итоге. Просто проходим по всем кластерам, и если где-то есть ссылка на "влитый", то меняем ее на ссылку на "увеличенный", в который вливали... Вот и все. Продолжать до
for(int i = 0; i < matrixSize; i++)
{
if(clusters[i].disabled) continue;
for(unsigned j = 0; j < clusters[i].Edges.size(); j++)
{
if(clusters[i].Edges[j].first == jj)
{
clusters[i].Edges[j].first = ii;
}
}
}
// ***
Если хочешь - я завтра попробую покумекать над сокращением кода, хотя тебе ж для QT - тогда многое будет непереносимо.
Автор: volvo 26.11.2009 22:41
main.cpp ( 9.12 килобайт )
Кол-во скачиваний: 630Автор: Andrewshkovskii 27.11.2009 4:04
Ох, только добрался до компа, весь день в институте просидел.. Так, сейчас скачаю и попробую разобраться.если что, надеюсь на твою благосклонность и отзывчивость (сможешь подтвердить или опровергнуть мои догадки насчет происходящих действий в коде:)
Автор: Andrewshkovskii 27.11.2009 17:44
Ну в общем я попробовал разобраться, все в исходнике (комментарии и вопросы), ещё одно хотелось бы понять точно :
Где именно у нас образуется/поглощается кластер в коде?
Для чего : что бы можно было нарисовать дендрограмму кластеров. А для этого нужно ещё добавить в класс кластер , его координату на визуальном объекте отрисовки.
Для отдельной вершины это будет координата Текстового значения , что бы можно было провести вот такое 
А для кластера, его центр (все изображено на рисунке). Т.е когда образуется кластер, или кластер поглошается, я буду вызывать сигнал, в котором буду передавать :
1. Кто поглотил
2. Кого поглотил
У меня в проекте есть маппер, для каждой вершины и её текстового значения на отображении, т.е. таким образом я смогу нарисовать кластер от одной вершины к другой, зная какое событие произошло : то ли поглощение, то ли образование.
Соответственно нужно разделение на :Создание кластера и поглощение кластера..
Прикрепленные файлы
main.cpp ( 9.12 килобайт )
Кол-во скачиваний: 382
Автор: volvo 27.11.2009 17:53
Насчет кластеров - сливаются кластеры здесь:
void MyCluster :: operator += (MyCluster& cL)Кто поглотил - this, кого поглотил - cL. Что касается создания - то можешь проверять длину vx, и если для обоих кластеров она = 1, то считай, что это раньше были 2 вершины, и они создали кластер.
Автор: Andrewshkovskii 27.11.2009 17:55
Упс, исходник вот.
Насчет длины вектора так и думал:)
Прикрепленные файлы
main.cpp ( 10.58 килобайт )
Кол-во скачиваний: 430
Автор: volvo 27.11.2009 18:55
Вот ответы:
(я оставил твои комментарии, ниже добавил свои /* вот такие */)
main.cpp ( 14.58 килобайт )
Кол-во скачиваний: 772
Автор: Andrewshkovskii 27.11.2009 21:10
Так, слегка проникся кодом, и даже что-то понял:)
Только одна ситуация. Предположим, что у нас есть некая структура данных, которая содержит визуальные координаты вершин (ну, например, vector <map <int , pos> >, где pos - координата x,y).И соответственно есть поле у класса Cluster такого же типа, только оно содержит :
1. Если кластер из одной вершины - то визуальную координату вершины.
2. Если в кластере вершин > 1 , то уже содержит визуальный центр кластера.
Предположим, что когда мы создаем кластер из одной вершины, и при создании координата вершины записывается в конструкторе.
Далее, когда мы сливаем кластер, нам необходимо изменить координату центра, т.е.
есть 2 кластера с одной вершиной(к1,к2) ,и кластер(из 1 вершины, но со значением sr > получившегося из образование к1 и к2 кластера) к3.
Вот что получается...
к1 и к2 объединяются. Вызывается метод, который визуально это отображает :
чертит из центра к1 в к2 "скобу" (можно увидеть на посте 16 что такое скоба) изменяем центр к1 на центр
скобы.
ВОПРОС : где удобнее будет вызывать этот метод отрисовки , в операторе += или после его выполнения?
(Ведь к1 теперь станет кластером с 2мя вершинами, ну, имеется ввиду, что к1 это clusters[ii].
2 шаг : К3 поглошает к1. Вызывается метод, который визуально это отображает
из центра К3 чертит "скобу" в центр кластера к1. тоесть из центра clusters[ii] в центра clusters[jj], и
изменяем центр К3 на центр новой "скобы"
По твоему мнению, такая логика будет достаточно верной?
Автор: volvo 29.11.2009 22:21
Написал код для визуализации на VCL (Билдер). Вот что получилось: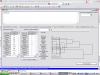
(если взять чуть более широкую панель, то все будет прекрасно отображаться, здесь масштаб маловат, поэтому одно налезает на другое...)
А теперь, собственно, КАК оно делалось:
1) в класс MyCluster введен еще один member под названием center, который хранит смещение от верха панели (фактически - координату Y кластера. Координата X нам не особенно нужна, есть srez). Ну, а потом, как только нашли очередной минимум:
outCanvas->Pen->Color = clBlack;Это отрисует "дерево". А уж на перемещение TrackBar-а вешаем:
outCanvas->MoveTo(visLabelWidth + 30 + clusters[ii].sr, clusters[ii].center);
outCanvas->LineTo(visLabelWidth + 30 + min, clusters[ii].center);
outCanvas->MoveTo(visLabelWidth + 30 + clusters[jj].sr, clusters[jj].center);
outCanvas->LineTo(visLabelWidth + 30 + min, clusters[jj].center);
outCanvas->LineTo(visLabelWidth + 30 + min, clusters[ii].center);
clusters[ii] += clusters[jj]; // Сливаем кластеры
clusters[ii].sr = min; // запоминаем, когда произошло слияние
std::for_each(clusters.begin(), clusters.end(),
Updator(std::make_pair(jj, ii))); // Обновляем ссылки на старый кластер
clusters[jj].disabled = true; // jj кластер убран
// Рисуем центр "Объединенного" кластера
outCanvas->Pen->Color = clRed;
int px = visLabelWidth + 30 + min, py = clusters[ii].center;
outCanvas->Ellipse(px - 2, py - 2, px + 2, py + 2);
res.push_back(clusters[ii]);
// Ну и так далее...
void UpdateClusterList(int srez, std::vector<MyCluster>& vec, TMemo* memo)
{
std::vector<MyCluster>::iterator it;
memo->Clear();
for(it = vec.begin(); it != vec.end(); it++)
{
if(it->sr >= srez)
{
memo->Lines->Add(it->ShowInfo());
// Показываем нужную информацию, я заменил вывод << методом ShowInfo()
}
}
}
void __fastcall TForm1::TrackBar1Change(TObject *Sender)
{
UpdateClusterList(((TTrackBar *)Sender)->Position, res, memResults);
}
Вот и все, теперь список кластеров будет содержать только те элементы, поле sr которых не меньше текущей позиции ТрэкБара, что и нужно было. Останется только рисовать эту красную линию при движении бегунка, для наглядности...

Автор: Andrewshkovskii 30.11.2009 5:26
Привет!:)спасибо за огромную помощь..но я пошел немного другим путем.
Я так же ввел для каждого кластера его центр.
Но вот соотношения значения ползунка и самого кластера на дендрограмме я пока не могу придумать как соотнести.
Да и потом, почему-то криво рисует.Точнее теряет центр нек. кластеров.
Вот как я сделал:
QPointF Model::drawClamp(const QPointF &from, const QPointF &to)//рисуем скобу
{
QPointF ptr;
//!! space - шаг, тестовый.
qreal x1,y1,x2,y2;
if (from.x() > to.x())
{
x2 = from.x()+3;
y2 = from.y();
x1 = to.x()+3;
y1 = to.y();
}
else
{
x1 = from.x()+3;
y1 = from.y();
x2 = to.x()+3;
y2 = to.y();
}
visualResultModel->addLine(x1,y1,x2+space,y1);
ptr.setY((visualResultModel->addLine(x2+space,y1,x2+space,y2))->line().length()/2);//середина вертик. линии ?
visualResultModel->addLine(x2+space,y2,x2,y2);
ptr.setX(x2+space);
qDebug() << ptr;
visualResultModel->addEllipse(ptr.x(),ptr.y(),2,2,QPen(),*(new QBrush(Qt::black,Qt::SolidPattern)));
space+=5;
return ptr;
}
и в коде вот так :
clusters[ii] += clusters[jj];
clusters[ii].setPos(drawClamp(clusters[ii].pos(),clusters[jj].pos()));
setPos, соответственно, устанавливает центр.
и для 5 значений получается такая белиберда:
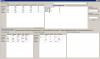
Автор: volvo 30.11.2009 5:48
Блин, у меня оказывается на скрине не было видно самой дендрограммы. Поправил... Теперь видно... Твой код завтра посмотрю, может чего и придумается...
Автор: Andrewshkovskii 30.11.2009 5:50
Ну я проект скину перед сном, если надо, посмотришь прям с возможностью компилирования.а пока сижу сам думаю..вроде чет наклевывается.
И я пока не настраивал ползунок, и не вывожу текущие кластера, сначала решил разобраться с дендрограммой...
Нашел, вроде ошибку математическую с вычислением центра линии.
visualResultModel->addLine(x1,y1,x2+space,y1);
visualResultModel->addLine(x2+space,y1,x2+space,y2);
visualResultModel->addLine(x2+space,y2,x2,y2);
ptr.setX(x2+space);
ptr.setY((y1+y2)/2);//y координата центра вертикальной линии.
Чертит, но не понятно:)
Есть проблема, когда линия одного кластера накладывается на другой..предвижу, что придется искать пересечения новой линии кластера с другой, и отодвигать кого-то...Ох уж это..
Проект вот тут
http://webfile.ru/4122061
Ну кластера считаются в методе Model::calculateNewClustresModel, там же и рисуются (я выше рассказывал где ).
Автор: Гость 1.12.2009 0:34
В общем проблема такая...надо как-то зафиксировать количество тиков( это полосочки вертикальные под скроллбаром) и узнать, на сколько пикселей расстояние от одного тика до другого.
сейчас доделаю вывод кластеров, и выложу проектик доработанный, и буду дальше кумекать..
Автор: -Volvo- 1.12.2009 1:12
Автор: Andrewshkovskii 1.12.2009 4:27
Там надо минимум в 0 устанавливать, таково требование гуев от преподователя.
А если делать так, как ты говоришь, что количество тикой это max-min +1, т.е max+1 (если минимум в 0) то при некоторых варианта (когда максимум 20000 или 49000) то будет ужас, а не слайдер...
Автор: volvo 1.12.2009 6:04
В таком случае у тебя нет другого варианта, кроме как считать, что Слайдер - это проценты, minimum = 0, maximum = 100, ширину слайдера ты знаешь, вычислить, какая ширина в пикселях у одного тика - не составит труда...
Но (опять это самое но, в самый неподходящий момент, да?) Допустим, у тебя последний срез - 40000, тогда 1 тик - это 400 единиц. И что будешь делать, если у тебя за один-единственный щелчок по СпинЭдиту пролетит десяток разветвлений дендрограммы? Ну, тут уж выбирать, либо делать так, как я написал чуть выше, в 26 посте, и до посинения щелкать на СпинЭдит, пока доберешься до очередной развилки графика, либо считать процентами и пропускать некоторые из развилок...
Есть еще один вариант:
Автор: Andrewshkovskii 1.12.2009 6:19
Была такая мысль у меня о фиксации каждого кластера , и потом, при щелчке по спин. эдиту проходить только определенные значения(то есть диапазон значений у спинЭдита будет диапазон срезов дендрограммы, и без конкретного шага, а при щелчке вверх - к след. разветвления, вниз - к предыдущему..) Я вот выбираю меж двух зол..
Автор: Andrewshkovskii 1.12.2009 6:52
Перечитал методичку..в общем-то можно и вовсе без слайдера сделать. Т.е. можно остановиться на варианте с спинЭдитом. Только вот как учитывать значения, ведь они без определенного шага идут, в разнобой.
т.е это либо писать алгоритм "перешагивания" , либо наследоваться от слайдера и переопределять метод инкрименции/декрименции значений.
Автор: Andrewshkovskii 1.12.2009 20:41
В общем вот что вышло у меня. осталась одна проблема : расстояния, на которых строятся след. кластера, получаются не "настоящими".
Т.е. расстояния "скоб" должны быть связаны с значением кластера, а не фиксированной координатой. Сейчас получается так, что при переход к одному кластеру нормаль идет, а на следующем может линия отброситься назад, хотя кластер посчитан правильно, а все из-за фиксированного значения space и немного не правильного алгоритма построения...А вот как связать - пока не придумал.. Есть мысли какие-нибудь по этому поводу? :/
Алгоритм...
QPointF Model::drawClamp(const QPointF &from, const QPointF &to, long int cut)
{
QPointF ptr;
qreal x1,y1,x2,y2;
if (from.x() > to.x())
{
x2 = from.x()+3;
y2 = from.y();
x1 = to.x()+3;
y1 = to.y();
}
else
{
x1 = from.x()+3;
y1 = from.y();
x2 = to.x()+3;
y2 = to.y();
}
visualResultModel->addLine(x1,y1,x2+space,y1); // нарисовать горз. линию
visualResultModel->addLine(x2+space,y1,x2+space,y2); // вертикальную
visualResultModel->addLine(x2+space,y2,x2,y2); // гориз. линию
ptr.setX(x2+space); // запоминаем позицию центра
ptr.setY((y1+y2)/2);
visualResultModel->addEllipse(ptr.x(),ptr.y()-2,3,3,QPen(Qt::red),
*(new QBrush(Qt::red,Qt::SolidPattern))); // рисуем кружочек...
space+=3.6; // инкремент расстояния
/* вот тут то и косяк, если образуется новый кластер (из 2х вершни),
то он будет левее предыдущих кластеров.. */
return ptr;
}
Автор: Andrewshkovskii 1.12.2009 21:42
С этой проблема ещё связано с отрисовкой кластеров для последней закладки (где 2 среза всего 1 и 2)..Т.е. надо как-то в зависимости от длины среза рассчитывать расстояние и рисовать, что бы правдиво было..
Прикрепленные файлы clusters.zip ( 14.49 килобайт )
Кол-во скачиваний: 279
clusters.zip ( 14.49 килобайт )
Кол-во скачиваний: 279
Автор: Andrewshkovskii 1.12.2009 22:08
outCanvas->MoveTo(visLabelWidth + 30 + clusters[ii].sr, clusters[ii].center);
outCanvas->LineTo(visLabelWidth + 30 + min, clusters[ii].center);
outCanvas->MoveTo(visLabelWidth + 30 + clusters[jj].sr, clusters[jj].center);
outCanvas->LineTo(visLabelWidth + 30 + min, clusters[jj].center);
outCanvas->LineTo(visLabelWidth + 30 + min, clusters[ii].center);
Вот тут, ты отрисовываешь кластер?Я просто не понимаю, зачем MoveTo, да и у линии почему-то всего 2 координаты..
Автор: Andrewshkovskii 1.12.2009 22:57
procedure MoveTo(X, Y: Integer); Перемещает текущее положение пера (свойство PenPos) в точку (X,Y).
Понятно..
Автор: volvo 2.12.2009 1:51
 А расскажи мне (ты свою модель лучше знаешь, чем мне копаться) - почему у тебя visualResultModel->width() изменяется? Ладно бы, изменялась только при переключениях закладок, так нет же:
А расскажи мне (ты свою модель лучше знаешь, чем мне копаться) - почему у тебя visualResultModel->width() изменяется? Ладно бы, изменялась только при переключениях закладок, так нет же:
QPointF Model::drawClamp(const QPointF &from, const QPointF &to, long int cut)
{
QPointF ptr;
qreal x1,y1,x2,y2;
if (from.x() > to.x())
{
x2 = from.x()+3;
y2 = from.y();
x1 = to.x()+3;
y1 = to.y();
}
else
{
x1 = from.x()+3;
y1 = from.y();
x2 = to.x()+3;
y2 = to.y();
}
// Для пробы взял 374, как ширину поля, в которое все будет выводиться, начиная с 50-ти
int curr_x = (374.0 / visualResultModel->width() * cut) + 50;
qDebug() << "width = " << visualResultModel->width();
visualResultModel->addLine(x1,y1,curr_x,y1);
visualResultModel->addLine(x2,y2,curr_x,y2);
visualResultModel->addLine(curr_x,y1,curr_x, y2);
ptr.setX(curr_x);
ptr.setY((y1+y2)/2);
visualResultModel->addEllipse(ptr.x(),ptr.y()-2,3,3,QPen(Qt::red),*(new QBrush(Qt::red,Qt::SolidPattern)));
return ptr;
}
// также был добавлен вывод
values.push_back(qMakePair(min,clusters[ii].pos().x()));
qDebug() << "min = " << min << ", pos = " << clusters[ii].pos().x();
Результат:
width = 114.25
min = 15 , pos = 99
width = 114.25
min = 16 , pos = 102
width = 114.25
min = 17 , pos = 105
width = 114.25
min = 51 , pos = 216
width = 220
min = 82 , pos = 189
width = 220
min = 88 , pos = 199
width = 220
min = 89 , pos = 201
width = 220
min = 92 , pos = 206
width = 220
min = 92 , pos = 206
width = 220
min = 94 , pos = 209
width = 220
min = 114 , pos = 243
width = 247
min = 122 , pos = 234
width = 247
min = 134 , pos = 252
width = 256
min = 156 , pos = 277
width = 281
min = 222 , pos = 345
width = 349
min = 288 , pos = 358
width = 362
min = 331 , pos = 391
width = 395
min = 424 , pos = 451
с какого перепуга ширина изменилась с width = 114.25 на width = 220 где-то между срезом-94 и срезом-114? Почему ты сразу (как только получаешь максимальный срез) не устанавливаешь ширину поля отрисовки - скажем, через sceneRect - в максимальное значение, или чуть больше, чтоб оставалось место справа? Список ребер есть, достаточно при их инициализации (там, где addEdge) найти максимум, и максимально возможный срез тебе уже известен.
Вот если это сделать, то можно будет использовать тот код, который я привел (возможно - с небольшими недоработками).
Автор: Andrewshkovskii 2.12.2009 2:38
Изменяется она потому, что она при первичной отрисовки списка вершин устанавливается в зависимости от длины отображаемого текста, т.е она изначально, при создании не ресайзитсья нормально( правда я даже не понял как её нормально ресайзить, постоянно появлялись скроллбары..в общем я испытывал муки, пол недели потратил на то, что бы разобраться с соотношением координат view и сцены..так и толком не понял).
А далее, когда начинает рисоваться дендрограмма то она автоматически ресайзится под "длины("вроде) новых айтемов..вот так я это поведение понимаю.
Ты предлагаешь устанавливать ширину поля для отрисовки в преобразованную каким-то образом размера макс. ребра?
Автор: volvo 2.12.2009 3:12
Угу... Именно:
// Это у тебя было ...
clustersCuts.insert(prevCut,(QVector<MyCluster>::fromStdVector(clusters))); // создаем 0 срез
int biggest_edge = numeric_limits<int>::min();
for(int i = 0; i < matrixSize; i++)
for(int j = 0; j < matrixSize; j++)
if(sm[i][j] > 0) {
clusters[i].addEdge(make_pair(j, sm[i][j]));//создаем ребра
biggest_edge = (sm[i][j] > biggest_edge) ? sm[i][j] : biggest_edge; // Добавляем
}
// А вот теперь попробуем поправить ширину поля вывода...
QRectF sR = visualResultModel->sceneRect();
sR.setWidth(biggest_edge);
visualResultModel->setSceneRect(sR);
// Ну, дальше все остается без изменений...
А в методе drawClamp:
QPointF Model::drawClamp(const QPointF &from, const QPointF &to, long int cut)Вот чего получается:
{
QPointF ptr;
qreal x1,y1,x2,y2;
if (from.x() > to.x())
{
x2 = from.x()+3;
y2 = from.y();
x1 = to.x()+3;
y1 = to.y();
}
else
{
x1 = from.x()+3;
y1 = from.y();
x2 = to.x()+3;
y2 = to.y();
}
// Оставляем 120 единиц для отрисовки названий городов.
// Можно там, где собственно выводятся названия запоминать максимальную ширину,
// можно здесь - примерно...
int starting = 120;
int curr_x = ((visualResultModel->width() - starting - 40) / visualResultModel->width() * cut) + starting;
visualResultModel->addLine(x1,y1,curr_x,y1);
visualResultModel->addLine(x2,y2,curr_x,y2);
visualResultModel->addLine(curr_x,y1,curr_x, y2);
ptr.setX(curr_x);
ptr.setY((y1+y2)/2);
visualResultModel->addEllipse(ptr.x(),ptr.y()-2,3,3,QPen(Qt::red),*(new QBrush(Qt::red,Qt::SolidPattern)));
return ptr;
}
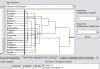
Сколько не щелкал "вперед/назад" - ни разу не было сбоя, куда говоришь, туда и перескакивает, к следующему кластеру - только вперед, к предыдущему - только назад.
Правда, иногда (когда срезы очень близко) Х-координаты совпадают, но это уже решается увеличением размера рабочей области, или добавлением прокрутки (сразу говорю, я с прокруткой не очень хорошо знаком, я бы советовал именно увеличить область, предназначенную для вывода дендрограммы. Возможно - за счет уменьшения ширины ячеек в "матрице измерений").
Автор: Andrewshkovskii 2.12.2009 5:07
Ну макс. длина у меня вычисляется, это я предусмотрел.
Спасибо за такую огромную помощь, даже не знаю как и отблагодарить.Сейчас буду тестировать...
Добавлено через 13 мин.
Ну..я не знаю, какая у тебя версия qt, но когда я расширяю сцену, то у меня при больших значениях я вообще практически ничего не вижу..вот так вот :![]()
Значит, надо брать какой-то процент, либо делить на сотые части значение biggest_edge..
Добавлено через 8 мин.
Ох..с вот с последней закладкой вообще цирк )
Исправил путем умножения cut и biggest_edge на 150 при условии, что они меньше 10..
Добавлено через 15 мин.
нашел значения, при которых "уплывает" дендрограмма
14946
24266
28933
2080
1080
920
873
607
буд думать как из резать, калечить, убивать..

Автор: volvo 2.12.2009 5:58
Делаем в drawClamp() вот так:
int starting = 120;, а описание biggest_edge переносим в класс Model, а не локально в этом методе. Тогда все закладки отображаются как положено. Я просто последнюю вообще не видел, она скрытная какая-то
// int curr_x = ((visualResultModel->width() - starting - 40) / visualResultModel->width() * cut) + starting;
int curr_x = ((visualResultModel->width() - starting - 40) / (qreal)biggest_edge * cut) + starting;
// Model::calculateNewClustersModel тоже чуть-чуть по другому
// А вот теперь попробуем изменить ширину поля вывода... Прописываем ЖЕСТКО: 400
QRectF sR = visualResultModel->sceneRect();
sR.setWidth(400);
visualResultModel->setSceneRect(sR);
Автор: Andrewshkovskii 2.12.2009 6:06
хм..действительно..
Над не забыть только biggest_edge обнулять при переходе на другую МОД(Закладку, или меняя кол-во записей)
В принципе осталось пофиксить 2 пункта :
1. Из-за того, что в последней закладке много одинаковых значений срезов текстовое отображение кластеров тупит
(я в принципе придумал решение в виде того, что при каждом новом срезе к его значению будет плюсоваться i, которая в свою очередь изменяется на 1 в основном цикле кластеризации)
2. ну и из-за этого же криво отображаются кластеры для той же закладки.
происходит это вот так :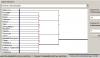
Ну есть мысль, что если изменять значение среза как-то по другому, для этой закладки, то удастся избавиться от этого.
Ну и небольшой шрих, что бы при уменьшении количества вершин, они заполняли сцену вертикально-равномерно, а не только с левого верхнего угла ..
Автор: Andrewshkovskii 2.12.2009 17:49
С 2ой проблемой разобрался, а вот что делать с 1ой.. Даже биндинги к этим значениям не придумаешь, ибо они одинаковые...
А логика отображения такая
есть 2 структуры данных
1.values хранит значения кластеров (т.е их срез) и их координату в порядке их формирования.
2.clustersCuts хранит срез(число) и набор кластеров для этого среза.
метод setTextModel(int) в который приходит значения среза, и по этому значению в clustersCuts ищется набор кластеров, и отображается..
Автор: Andrewshkovskii 3.12.2009 4:14
Ну в общем дописал..нашел правда один мемори лик, но исправлять не хочу, и лень и никому это не надо, кроме меня(в смысле не оценят..) Огромное спасибо volvo и его коту за помощь!:)
Автор: finasteride 1 mg no prescription 29.10.2021 23:10
Cytotec Pills Over The Counter
Автор: gabriella 12.04.2022 10:27
Your writings and news are really interesting to me. There are numerous advantages to the contents. Thank you so much. My site:: https://www.chokdeebacarrat.com/ole777/
Автор: reznit 9.06.2022 15:17
Доступа к определенному элементу (кроме первого) просто не существует.
Автор: nishaknapp 29.07.2022 16:56
Why not settling on games that is fun and at the same time your earning. Well itll make suspense because of the game as well but dude just try it and it gave me hope while pandemic is real rn. https://www.anybirthday.com/money/master-the-art-of-playing-baccarat-in-online-casinos/
Автор: gabriella 1.08.2022 9:37
It is the intent to provide valuable information and best practices, including an understanding of the regulatory process.
https://freespinsslots6.org
Добавлено через 15 мин.
It is the intent to provide valuable information and best practices, including an understanding of the regulatory process.
https://zipang-bar.com