Версия для печати темы
Нажмите сюда для просмотра этой темы в обычном формате
Форум «Всё о Паскале» _ Алгоритмы _ Оптимизация
Автор: Caranthir 11.12.2006 17:34
Подскажите плиз)
Файл содержит не более n (от1 до 1.000.000) положительных чисел, каждое из которых не превышает 10^7 (телефонный номер). Все номера в файле уникальны. Присутствие дубликата считается ошибкой.
Результат.
Упорядоченнный по возрастанию список целых чисел, каждое из которых не превышает 10^7. На выходе должен быть получен файл отсортированных по возрастанию номеров.
Ограничения.
~1Мб ОП. место на диске не ограничено. время выполнения не должно превышать нескольких минут, если оно будет сокращено до нескольких секунд, то дальнейшая оптимизация не требуется.
Автор: klem4 11.12.2006 18:05
Эм ну ты бы показал свой вариант, а то что оптимизировать-то ? Да и глупо получится если кто-то сделает программу такую-же как у тебя ...
Или у тебя вообще мыслей нету никаких по поводу решения ?
Автор: Malice 11.12.2006 18:29
Файл текстовый ? Может есть смысл переписать его в типизированный (file of longint), потом отсортировать любым способом и назад..
Автор: hiv 11.12.2006 18:34
Первое, что приходит на ум:
1) Последовательно прочесть исходный файл, при этом одновременно писать прочитанные данные во временные файлы с именами от 00 до 99 в соответствии с первыми двумя цифрами телефонного номера.
2) в цикле читать файлы с 00 по 99, сортируя телефонные номера по возрастанию. После сортировки каждый раз дописывать результат в итоговый файл. Быстрый метод сортировки подсказать трудно, т.к. объем вычислений предугадать невозможно (от 1 до 1 000 000).
Есть вопрос - могут ли номера телефонов начинаться с 0?
ЗЫ: На чем реализовывать будете?
Автор: Caranthir 11.12.2006 18:48
Мысли:
При объёме ОП в 1 Мб туда можно забросить ~ 250000 чисел. ->
1. исходный(текстовый) файл разбивать отдельные файлы и сортировать по символам т.к. числа записаны в файле в виде строк
2. Разбить на ~256 (если орентироваться по байтам) файлов и сортировать по-байтам
а потом каждый отсортированный записывать в файл-результат

Файл текстовый ? Может есть смысл переписать его в типизированный (file of longint), потом отсортировать любым способом и назад..
А это намного быстрее?
Первое, что приходит на ум:
1) Последовательно прочесть исходный файл, при этом одновременно писать прочитанные данные во временные файлы с именами от 00 до 99 в соответствии с первыми двумя цифрами телефонного номера.
ЗЫ: На чем реализовывать будете?
на Delphi
во-во, а по-байтам сортировать может ли это быть быстрее?
Автор: hiv 11.12.2006 18:51
Еще раз повторю - могут ли номера телефонов начинаться с 0?
От этого зависит прийдется тебе работать с просто числами или со строками. Если есть ноль в начале, то - со строками. Если так, то количество цифр в номере всегда одно и тоже, тогда можно использовать не string, а массив из char (экономиться один байт - длина строки).
Далее - сортировка не байтами! Чтобы хранить номер нужна либо строка (минимум 7байт) либо DWORD (4байта).
Автор: Caranthir 11.12.2006 18:55
Неа, нулей нет
А если разбивать на файлы, тогда кол-во чисел в каждом оставит около 10.000, подскажите каккую лучше сортировку применить?
Автор: Lapp 11.12.2006 19:03
От этого зависит прийдется тебе работать с просто числами или со строками.
Не понимаю, что меняет наличие нулей в начале? число как число, только при выводе его нужно добить нулями слева..
Автор: hiv 11.12.2006 19:03
 Тогда номер телефона можно спокойно хранить в типе longint (Delphi) - 4байта
Тогда номер телефона можно спокойно хранить в типе longint (Delphi) - 4байта
и пользоваться динамическим массивом из 250 000 longint. Соответственно - 4 временных файла.
Вопрос следующий - 1Мбайт ограничения только на данные связанные с номерами телефонов или на всю память, что программа будет занимать вместе с кодом?
К стати longint сравниваются просто < > =
2Lapp: Номера могут быть и разной длины... К стати тоже вопрос - позвоните 09
Автор: Caranthir 11.12.2006 19:07
"для хранения данных в системе может быть выделено до 1 Мб"
Автор: hiv 11.12.2006 19:10
http://forum.pascal.net.ru/index.php?showtopic=3065&hl=%F1%EE%F0%F2%E8%F0%EE%E2%EA%E0
Автор: Caranthir 11.12.2006 19:16
А вот если разбивать на 4 файла по 250000, тогда придётся отсортировав каждый, совмещать отсортированные
-> наверное надо разбить на кратные (или 2 или 10)
а, следовательно что может быть быстрее отсортированно и объединено 1000 файлов по 1000 или же 10 по 100000???
http://forum.pascal.net.ru/index.php?showtopic=3065&hl=%F1%EE%F0%F2%E8%F0%EE%E2%EA%E0
Спс конечно за ссылку, но я уже её прочитал)))
там нету на 1000000))
хм...и поразрядная что-то не компил(
Автор: Lapp 11.12.2006 19:18
2Lapp: Номера могут быть и разной длины... К стати тоже вопрос - позвоните 09
это, конечно, верно. Но в условии автор ясно сказал: "числа" - и при этом добавил, что нет равных. Следовательно, 09 и 9 не могут встретиться в одном файле.
Но я уже понимаю, что автор на самом деле имел в виду все же телефонные номера, то есть строки символов, что есть абсолютно не числа, на самом-то деле.. Может, он думал, что искажая условие, облегчает задачу?..
Помимо прочего, тема абсолютно не на своем месте. Переношу в Алгоритмы.
Автор: Michael_Rybak 11.12.2006 19:27
Проблема с ведущими нулями решается временным дописыванием перед номером одной цифры, равной его длине При этом, сравнивая числа во время сортировки, нужно это учитывать, а как именно - зависит от того, могут ли быть номера "09" и "0009", и если да, то как их сравнивать.
А дальше -
Даже если группировать по 100 000 лонгинтов (тогда и с кодом вместе легко впишемся в 1 МБ), получится 10 групп. Сортировка каждой из них в ОП - порядка 100 000 * log 100 000, слияние в один файл - 1 000 000 * 10 (можно и 1 000 000 * log 10, но зачем?). Должно работать за несколько секунд.
Кстати, скорость может еще существенно зависеть от ввода-вывода. Например, в С++ ввод/вывод такого объема данных с помощью fstream (а не file) займет больше времени, чем собственно сортировка.
следовательно что может быть быстрее отсортированно и объединено 1000 файлов по 1000 или же 10 по 100000???
Если мы разбиваем n чисел на группы по q чисел в каждой, то сортировка всех групп займет O(n/q * (q log q)) = O(n log q), слияние - O(n * log (n / q))
Итого имеем O(n log q) + O(n log (n / q)) = O(n max (log q, log (n / q))). Из этого следует, что оптимальнее всего выбирать q равным sqrt(n). НО! Это - с точки зрения асимптотики. С практической же точки зрения нужно еще учесть
1) время на работу с файлами
2) ненужность приведенных оценок
Реально, делай q хоть 1000, хоть 10, для таких ограничений будет летать.
Автор: Caranthir 11.12.2006 19:29
хм...нечего я не искажал. Файл текстовый-> номера там находящиеся явл строками.
и всё же подскажите пож. как "правильнее" разбить данный файл и в каком формате обрабатывать?
Автор: Caranthir 11.12.2006 19:42
Respeсt кто помогал))
Автор: klem4 11.12.2006 20:15
Кстати не стоит забывать о том, что после разбиения то придется все это дело "сливать" ... не особо то это бытро будет )
Автор: hiv 11.12.2006 20:32
2klem4: При использовании буферного чтения записи во временных файлах (к стати их лучше тоже делать типа longint), это будет существенно быстро.
Автор: Caranthir 11.12.2006 20:47
не совсем понял..Поясни пжл как осуществить буферное чтение программно
Автор: Michael_Rybak 11.12.2006 21:30
Кстати не стоит забывать о том, что после разбиения то придется все это дело "сливать" ... не особо то это бытро будет
)Это будет не намного медленнее, чем считывать данные из входного файла. В пределах нескольких секунд.
А буферное чтение тут, по-моему, не причем - нам же между собой номера из разных файлов все время сравнивать надо при слиянии.
Автор: Caranthir 11.12.2006 21:55
При сливании сравниваются только номера самих файлов.
Возможный вариант:
в каждом файле иммется упорядоченный массив из чисел, таких как <само число>-<номер файла>, а в файл-результат записываются последовательно все числа из файлов +номер файла в порядке прочтения файла
Автор: Michael_Rybak 11.12.2006 22:52
А как ты разбросаешь по файлам, чтобы в первом файле шли подряд с первого по q-й, во втором - с q+1 по 2q-й и так далее?
Автор: Caranthir 11.12.2006 23:15
прочитать весь массив, создать дополнительные файлы и разбрасать по ним числа(в процессе чтения), различающиеся первыми 2 цифрами
а читать с 1 по 2500000 и тд
Автор: Michael_Rybak 12.12.2006 2:09
А если все номера начинаются на одни и те же две цифры? Не, если номера случайные, тогда конечно. Я говорю про решение, работающее в худшем случае.
Автор: Caranthir 12.12.2006 3:19
Хм...Ты прав.
Если одинаковых чисел >250000 брать эти чсла с меньшими разрядами))
Автор: Michael_Rybak 12.12.2006 3:38
Чтобы работало в любом случае, надо
1) разбить просто подряд: первые q номеров - в первую группу, следующие q - во вторую и т.д.
2) по очереди каждую группу отсортировать и записать в файл
3) идти по файлам одновременно, выбирая на каждом шагу наименьший из текущих номеров в файлах
Это похоже на сортировку слияниями (точнее, это и есть сортировка слияниями), только сливаем мы не два списка, а больше.
Автор: Caranthir 12.12.2006 4:57
Интересно... попробую
Спасибо
Автор: hiv 12.12.2006 13:09
Ну хорошо. Можно попробовать обоими способами и сравнить результаты
Автор: Malice 12.12.2006 13:39
Вот вам генератор файлов для экспериментов:
procedure generate;
var f:file of longint;
f2:text;
i,q,w,e,r:longint;
s:string;
function rnd(i:longint):longint;
var x:longint;
begin x:=longint(random($ffff))+longint(random($ff))*$ffff; rnd:=x mod i; end;
begin
assign (f,'test1.dat'); rewrite(f);
randomize;
for i:=1 to 1000000 do write(f,i);
close(f); reset(f);
for i:=0 to 1000000-1 do begin
w:=rnd(1000000);
seek(f,i); read(f,e); seek(f,w); read(f,r);
seek(f,i); write(f,r); seek(f,w); write(f,e);
end;
reset(f);
assign (f2,'test1.txt'); rewrite(f2);
repeat
read(f,i);
str(i,s);
writeln(f2,s);
until eof (f);
close(f); close(f2);
writeln(1);
close(f);
end;
Автор: hiv 12.12.2006 14:30
Входной формат файла - текстовый. Данные не должны повторяться.
Я сам уже нагенерил файло, конечно
Автор: Malice 12.12.2006 14:33
Входной формат файла - текстовый. Данные не должны повторяться.
У меня так и есть, результат в 'test1.txt', .dat промежуточный, там перемешивается все просто..
Автор: Altair 12.12.2006 19:33
ИМХО (по основной задаче)
Портируем текстовый файл в типизированный из longint'ов. (10^7 вместит), причем "на лету".
(в памяти есть longint переменная, куда суммируем каждый раз текущую цифру * на 10 в соотв. степени, и обнуляем этот long при переходе через разделитель, записывая его при этом в long file)
Никаких сортировок не производим!
В момент сбрасывания очередного longint в типизированный файл, скидываем его, позиционировав указатель (seek) на его номер! (для этого заранее стоит выделить место под файл, это - 1 действие)
Далее просто тупо копируем типизированный файл в текстовый, причем если место пусто, то пропускаем номер.
Данный метод позволит получить результат без сортировки вообще.
Метод применяют при ограниченных вычислительных способностях и больших объемах памяти (в нашем случае внешняя память доступна)
Кратко я показал данный алгоритм на схеме: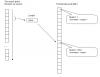
Автор: Michael_Rybak 12.12.2006 20:12
Круто, риспект
Только опять непонятно, как быть с номерами "009" и "000009"
Но эту проблему, как я уже писал, можно решить дописыванием в начало длины.
Автор: Altair 12.12.2006 20:35
А такие номера могут существовать?
Если да, дописывать после них 0 а не до!
Я точно знаю, что 100 и 1000000 это один номер (проверял
)АТС работает "посимвольно" как только номер совпал - ура, соединили!
Так что 100 и 100xxxx это одно!
Автор: hiv 13.12.2006 16:15
Вот первый вариант.
Номера разбрасываются по 90 временным файлам в соответствии с первыми двумя цифрами номера.
Везде буферный ввод вывод.
Сортировка типа radix битовая (оказалась самой быстрой, ускоренный пузырек более 40сек работал).
Итого:
Входной файл текстовый без повторяющихся номеров - 9 000 000 байт (1 000 000 номеров).
Время работы 4,157 сек. Кто быстрее? 
Максимум выделяемой динамической памяти на данные не превысил 742900 байт.
Выходной файл текстовый с отсортированными номерами - 9 000 000 байт (1 000 000 номеров).
Программа -  telsort1.zip ( 2.61 килобайт )
Кол-во скачиваний: 450
telsort1.zip ( 2.61 килобайт )
Кол-во скачиваний: 450
(обновлена)
Параметры машины:
ОС - WinXP
Процессор - Pentium4 1.8ГГц
ОЗУ - 512 Мб
Винт - 40Гб 7200об/мин
ЗЫ: Берусь теперь за второй вариант, предложенный Michael_Rybak.
Если у кого есть предложения по оптимизации готового кода - буду рад
Автор: Malice 13.12.2006 17:29
Входной файл текстовый без повторяющихся номеров - 9 000 000 байт (1 000 000 номеров).
Т.е. Все числа выровнены и добиты в начале 0-ми ? А как же пожарные/милиция ?
Тогда это типизированный файл получается..
Автор: hiv 13.12.2006 18:35
Т.е. Все числа выровнены и добиты в начале 0-ми ? А как же пожарные/милиция ?
Тогда это типизированный файл получается..Неа
 см. пост7
см. пост7А на самом деле в телефонии нумерация символьная, и "добивать" слева нулями нельзя - тогда разные номера получаться. 01 и 001 - разные. Да и справа тоже нехорошо. На одной станции можно такой номер прописать 0101, а на другой 01010 - это тоже разное. Так что сказано 7-значка без нулей в начале, так и сделано.
Автор: Michael_Rybak 13.12.2006 21:07
Вот первый вариант.
Номера разбрасываются по 90 временным файлам в соответствии с первыми двумя цифрами номера.
Везде буферный ввод вывод.
Сортировка типа radix битовая (оказалась самой быстрой, ускоренный пузырек более 40сек работал).
Итого:
Входной файл текстовый без повторяющихся номеров - 9 000 000 байт (1 000 000 номеров).
Время работы 4,157 сек. Кто быстрее?
Максимум выделяемой динамической памяти на данные не превысил 742900 байт.
Выходной файл текстовый с отсортированными номерами - 9 000 000 байт (1 000 000 номеров).
Программа - [attachmentid=4494]
Параметры машины:
ОС - WinXP
Процессор - Pentium4 1.8ГГц
ОЗУ - 512 Мб
Винт - 40Гб 7200об/мин
ЗЫ: Берусь теперь за второй вариант, предложенный Michael_Rybak.
Если у кого есть предложения по оптимизации готового кода - буду рад
Еще можно попробовать поразрядную сортировку (т.е. по 10 файликов разибвать и сливать 8 раз). Напишешь?
Автор: hiv 13.12.2006 21:41
Еще можно попробовать поразрядную сортировку (т.е. по 10 файликов разибвать и сливать 8 раз). Напишешь?
Поподробнее, а то твоя моя не понимай...
Подумал на счет твоих постов 14 и 20 - с битовой сортировкой не получится:
7-мизначка = 9 000 000 номеров
делим на 8 бит = 1125000 байт
что больше 1Мбайта

А использовать пузырек - не поможет (по объему около 40 сек выйдет).
Автор: Michael_Rybak 13.12.2006 22:05
Есть т.н. ковшовая, или поразрядная сортировка.
Ковши = файлы.
Есть 1 исходный ковш (большой), и 10 малых, пронумерованных от 0 до 9.
Идем по большому ковшу, разбрасываем по малым все числа, в зависимости от последней цифры (младшего разряда).
Потом сливаем малые ковши в порядке возрастания в большой ковш.
Потом то же самое, но уже по второй с конца цифре (десятки), потом - с третьей и так до 10^8.
7-мизначка = 9 000 000 номеров
делим на 8 бит = 1125000 байт
что больше 1Мбайта
А использовать пузырек - не поможет (по объему около 40 сек выйдет).
А вот тут уже моя твоя
Что такое битовая сортировка?
Автор: Caranthir 14.12.2006 2:32
блин....слабо пока, много получаетсся))
и....ээ...последние номера то не сортируются, кроме как по именам файлов, только первые
8971947
8962540
8916484
8912716
8941187
8915338
8971871
8923658
8938009
8929848
8910452
8982093
8940902
8941257
8942629
8961911
8985513
8948864
8976854
8953015
8960296
8933310
8987267
8987947
8982026
8912167
8950310
8938580
8982516
8981755
8987127
8936605
8994136
Автор: hiv 14.12.2006 13:54
Потом то же самое, но уже по второй с конца цифре (десятки), потом - с третьей и так до 10^8.
Что такое битовая сортировка?
8961911
8985513
8948864...
Автор: Caranthir 14.12.2006 16:41
Не стесняйся - программу в студию
Это я твою смотрел и так отсортировалось_)
Могу только на С++ показать, на Pascal пока никак
Автор: hiv 14.12.2006 17:16
Могу только на С++ показать, на Pascal пока никак
значит у тебя дубликаты номеров есть... Тогда переделай код так: замени count на j
// запись результата сортировки в итоговый файлна
ps:=pbuff;
pe:=pbuff+buff_count;
for k:=0 to count-1 do
begin
// запись результата сортировки в итоговый файл
ps:=pbuff;
pe:=pbuff+buff_count;
for k:=0 to j-1 do
begin
и будет счастье

Автор: Michael_Rybak 14.12.2006 20:06
А я думаю что не будет
Это когда сортируем неповторяющиеся числа. Мы можем однозначно сопоставить значеням этих чисел порядковые номера битов в битовом массиве, т.е. число 5432167 будет означать, что 5432167-й бит установлен в единицу. В итоге максимальный размер битового массива в байтах = максимальное значение числа / 8 бит. Потом проходим битовый массив с первого по последний и последовательно записываем номера битов установленных в единицу в сортируемый массив чисел. Допустим значения чисел не превышают 10^7, то размер битового массива в байтах (10^7)/8=1 250 000, что сопоставимо с размером массива хранения самих чисел (в нашей задаче 1 000 000 чисел * 4байта= 4Мб). Конечно если чисел немного, то данный алгоритм не эффективен с точки зрения потребляемой памяти, а если совсем мало - то и медленнее всех других алгоритмов, ибо размер битового массива никак не зависит от количества сортируемых чисел.
Угу, понятно. Прикольно.
Автор: klem4 14.12.2006 23:06
http://forum.pascal.net.ru/index.php?s=&showtopic=3065&view=findpost&p=32464

Автор: Michael_Rybak 14.12.2006 23:11
Вот битовой там, если не ошибаюсь, нет.
Автор: hiv 15.12.2006 15:45
Вот второй вариант сортировки (просто супер):
1) Читаем исходный файл насколько влазиет в память, потом сортируем и сохраняем во временный файл, следующая итерация чтения исходного файла также сортируется и заносится в следующий временный файл. Т.о. чем меньше памяти на данные мы выделяем, тем больше временных файлов. Сортировка проводится методом "Быстрой сортировки" описанной в FAQ и взятой от туда
2) Сливаем все временные файлы в итоговый, каждый раз выбирая минимальное значение среди прочтенных из всех временных файлов.
Также везде буферный ввод вывод.
Спасибо Volvo за FAQ и Michael_Rybak за метод сортировки слияниями файлов. См. пост 26
Итого:
Входной файл текстовый без повторяющихся номеров - 9 000 000 байт (1 000 000 номеров).
Время работы 3,421 сек. Кто еще быстрее? cool.gif
Максимум выделяемой динамической памяти на данные не превысил 970372 байт.
Выходной файл текстовый с отсортированными номерами - 9 000 000 байт (1 000 000 номеров).
Программа -
telsort2.zip ( 2.98 килобайт )
Кол-во скачиваний: 479
Параметры машины: теже
ЗЫ: К стати обновил первую версию - теперь повторяющихся номеров в итоговом файле не будет, даже если они были в исходном. См. пост 35.
Во втором методе повторяющиеся номера не удаляются.
Автор: Michael_Rybak 15.12.2006 18:20
Круто, спасибо, что пробуешь
У меня еще вот какая идея возникла: можно твою битовую модифицировать, чтобы в память влезло. У тебя получилось (10^7)/8=1 250 000, что немного больше позволенного. Тогда можно пройтись по входному файлу два раза: первый раз обрабатывая только числа, меньшие 10^7/2, а остальные пропуская, а второй раз - наоборот; памяти тогда понадобится в 2 раза меньше.
Автор: hiv 15.12.2006 20:30
2Michael_Rybak
Стыдно что сам до этого не додумался... Конечно попробую сделать этот вариант. Ну и ковшовую тоже попробуем 
Автор: Michael_Rybak 15.12.2006 21:32
Давай, ждем
Автор: Caranthir 18.12.2006 1:53
немного переделал твою первую версию hiv:
(с) и результат прилагается)
telsort1.zip ( 2.12 килобайт )
Кол-во скачиваний: 372
PS/ самому плохо думается
Автор: hiv 18.12.2006 13:42
Плохо переделал

Во первых использование меток считается плохим тоном программирования на паскале и может вызывать кучу завуалированных ошибок.
В вторых теряется смысл битовой сортировки, ты по индексу [tel[k]-sdvig] массива rad производишь обычный подсчет количества дубликатов номера tel[k], а потом еще их распечатываешь в итоговом файле в том же дублированном количестве... А как же условие задачи?
Так что подумай на досуге

Автор: hiv 18.12.2006 14:01
В третьих: функция setlength() - не обнуляет массив, в итоге у тебя могут появиться номера, которых в твоем исходном никогда небыло... (сравни размеры твоего исходного файла и файла с результатами сортировки - первый признак наличия ошибки).
Автор: hiv 18.12.2006 17:31
Вот третий вариант сортировки (супер твикс):
1) Определяем диапазон номеров которые будем читать и сразу сортировать битовой сортировкой.
2) Прочитываем весь файл и обрабатываем только те номера, которые входят в диапазон.
3) Сохраняем результат сортировки текущего диапазона в итоговый файл.
4) Берем следующий диапазон чисел и заново перечитываем исходный файл, т.е. переходим к пункту 2 Заканчиваем тогда, когда диапазон рассматриваемых чисел выходит за максимальный номер, в данном случае 10^7.
Никаких временных файлов на диске не создается. В данной задаче исходный файл прочитывается всего два раза. Также везде буферный ввод вывод.
Спасибо Michael_Rybak за подсказку. См. пост 49
Итого:
Входной файл текстовый без повторяющихся номеров - 9 000 000 байт (1 000 000 номеров).
Время работы 3,657 сек. Что почти догнало метод быстрой сортировки cool.gif
Максимум выделяемой динамической памяти на данные не превысил 978556 байт.
Выходной файл текстовый с отсортированными номерами - 9 000 000 байт (1 000 000 номеров).
Программа -
telsort3.zip ( 2.32 килобайт )
Кол-во скачиваний: 404
Параметры машины: теже
Автор: Michael_Rybak 18.12.2006 18:57
Прикольно
Автор: hiv 19.12.2006 21:13
Вот четвертый вариант сортировки (всем по ковшу):
Метод довольно подробно описан Michael_Rybak в этой теме (см. пост 40). Добавлю, что не использовал слитие номеров в общий ковш, как рассказывал Michael_Rybak, а просто считывал последовательно из 10 временных файлов и одновременно записывал в другие 10 временных файлов. Потом на каждом шаге просто менял эти две группы временных файлов местами, т.е. то что записывал - начинал читать от туда и наоборот. 20 временных файлов - это не так много
Также везде буферный ввод вывод.
Итого:
Входной файл текстовый без повторяющихся номеров - 9 000 000 байт (1 000 000 номеров).
Время работы 3,765 сек. Что обогнало первый метод я в шоке  думал что медленнее будет.
думал что медленнее будет.
Максимум выделяемой динамической памяти на данные не превысил 376 404 байт. (в принципе ничего кроме буферов чтения записи)
Выходной файл текстовый с отсортированными номерами - 9 000 000 байт (1 000 000 номеров).
Программа -
telsort4.zip ( 2.67 килобайт )
Кол-во скачиваний: 382
Параметры машины: теже
ЗЫ: Все я выдохся... Да и надоело уже...
Автор: Michael_Rybak 19.12.2006 21:22
а просто считывал последовательно из 10 временных файлов и одновременно записывал в другие 10 временных файлов

ЗЫ: Все я выдохся... Да и надоело уже...
Ничего себе выдохся
Перепробовал столько Супер!
Автор: hiv 19.12.2006 21:58
Спасибо! 
Автор: Caranthir 22.12.2006 3:02
Спасибо!!!
Всем кто развивал тему.
Особо признателен Michael_Rybak и hiv. Молодцы! 
