1. Заголовок или название темы должно быть информативным 2. Все тексты программ должны помещаться в теги [CODE=asm] [/CODE] 3. Прежде чем задавать вопрос, см. "FAQ",если там не нашли ответа, воспользуйтесь ПОИСКОМ, возможно, такую задачу уже решали! 4. Не предлагайте свои решения на других языках, кроме Ассемблера. Исключение только с согласия модератора. 5. НЕ используйте форум для личного общения! Все, что не относиться к обсуждению темы - на PM! 6. Проверяйте программы перед тем, как выложить их на форум!!
Я так понял, что каждое обращение к памяти, встречающееся в программе, долго и упорно обрабатывается системой на предмет залезания не туда, и если действительно было нарушение, вызывается обработчик исключения. Я сделал одну процедуру, у которой основной рабочий цикл (заполнении линии одинаковым, пока что, значением) выглядел так:
// заполнение регистра ecx длиной участка... jle @@; @: mov [eax], edx add eax, 4 // sub eax, 4 dec ecx; jnz @; @@:
Сделал замер скорости. Огорчился. Решил смеха ради добавить одну паразитную команду (она тут закомментирована). Получил резкое ускорение - то есть теперь данные стали выводиться в одно и то же место в памяти. Видимо система запомнила, куда в последний раз обращалась программа и не стала проверять обращение на корректность лишний раз. Как на самом деле обрабатываются обращения к памяти в винде? И можно ли использовать эту информацию для ускорения? Кстати, почему пара deс; jnz работает намного быстрее, чем loop, который специально предназначен для циклов?
Во-первых, не факт, что на всех процессорах будет тот же эффект. Давай сделаем так: приведи простейшую программку, которая будет использовать LOOP, и которая будет использовать DEC+JNZ, и сравнивать скорости их выполнения. И протестируем эту программку на разных процессорах. Скажем, на DualCore, QuadCore, P4, на Селеронах, на AMD-шках, можно на i7 попробовать потестировать... Я уверен, результаты будут не такими уж однозначными.
procedure Delay2; begin asm mov ecx, $FFFFFFF @: dec ecx; jnz @; end; end;
begin
T := GetTickCount; while T = GetTickCount do; T := GetTickCount; Delay1; i := GetTickCount - T; WriteLn('loop: ', i);
T := GetTickCount; while T = GetTickCount do; T := GetTickCount; Delay2; i := GetTickCount - T; WriteLn('dec;jnz: ', i);
ReadLn; end.
> Во-первых, не факт, что на всех процессорах будет тот же эффект.
То есть чаще будет наоборот и поэтому имеет смысл сделать луп? Вот дельфийский компилятор тоже делает через вычитание, причём почему-то в качестве счётчика цикла выбран ebx. Ещё забавный эффект - если перед циклом записать что-то в стек и сразу извлечь обратно, то получится полуторакратное замедление.
> см. здесь
Ща почитаю.
> P.S. Перенести в Ассемблер?
Подтему с циклами - да. Но меня больше интересовала скорость заполнения фрагмента памяти, а она, мне кажется, связана с особенностями системы.
> А заменить dec ecx на sub ecx,1 не пробовал?
Если в исходном виде поменять - эффекта ноль. Усилил эффект, убрав всё тело цикла, заметил полуторакратное замедление суба по сравнению с деком. Луп же вышел ещё вдвое медленне суба.
В рабочем цикле будет заполняться экранный буфер цветом примитива, с учётом тумана и будет заполняться з-буфер. Если что, на моей видяхе изобретение велосипедов очень даже оправдано.
Так что, пока разговор ни о чем. Если есть какой-то конкретный кусок кода, который надо оптимизировать, потому что ты точно знаешь, что в нем содержится проблема, и именно он не дает твоей программе работать как положено, а не какой-то наведенный эффект из другой части программы, то давай продолжим... Но для этого тебе надо по меньшей мере прогнать свой код через профилировщик, причем не раз и не два, и на большом количестве повторений. Ну, это все есть у Касперски, я ж не буду сейчас перепечатывать сюда всю книгу...
Я не просто так спросил, если что. Я бы не стал задавать вопрос, если бы сам код закраски полигона у меня не был готов. Причём большие полигоны у меня закрашиваются медленнее, чем опенглом, а маленькие - быстрее. Это говорит о том, что у меня тормозит внутренний цикл. То есть, как я понял, проблема с fillrate. У меня внутренний цикл написан на асме, рядом стоит его закомментированная копия на Паскале, чтобы, если что, вернуться и перепроверить алгоритм.
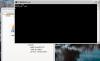
Результаты скорости меня интересуют, в первую очередь, для моего компьютера. Я рассуждаю так - что идёт у меня, то пойдёт у всех остальных. Вот скрин. Сверху - моя заливка полигона (в одном месте вместо мов поставлен ксор для красоты, он на скорость не влияет), снизу - опенгл. В заголовке - сколько миллисекнуд заняла скольки-кратная отрисовка сцены.
Так в виндовсе память работает в защищённом режиме, имхо, на конечном этапе ресурсами распоряжается менеджер памяти. При выводе картинки задействуется малый объём ресурсов, ситуация напоминает оплату электричества: при низком потреблении за почтовые услуги нужно постоянно платить в разы больше чем за потреблённую энергию (привет экономичным лампочкам)). Если занять у менеджера памяти ~100Мб (или больше) памяти и не дать ему усомниться в том что она нужна приложению всегда и полностью, статистика скорости доступа должна быть более точной. Это только скорость оперативки, видеокарты, отдельный вопрос.