минимального остовного дерева группируются в кластеры.
Выбираются два объекта, которым соответствует минимальное ребро minjdj,
где j=1, n-1. Далее эти объекты стягиваются в один кластер (класс, таксон, страту) и
процедура шага 2 повторяется до тех пор, пока на n-1 этапе группирования не будет
сформирован один кластер, объединяющий все объекты. STOP.
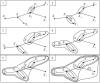
На рис. представлена последовательность группировки объектов в
кластеры для заданного на рис.1 примера минимального остовного дерева.
Порядок объединения объектов в кластеры отображён на рёбрах, которые
связывают объединяемые объекты .Таким образом, первыми
объединяются объекты X4 и Х5,которые в МОД связывает минимальное ребро d4
с весом 2. Вторыми объединяются объекты X2и X3, связанные ребром d2
с весом 3 , и так далее, пока на шестом этапе группирования ранее связанные объекты (X1,X2,X3,X4,X5,X6)
не будут объединены с объектом X7 ребром с весом 7.
И так , перейдем к описанию алгоритма кластеризации на примере :
Ребра МОД :
Цитата
(ИЗ--ВЕС-->В);
1. Е--2328-->Ом
2. В--2732-->И
3. Е--4667-->П
4. Л--5161-->Ом
5. О--6588-->И
7. П--14946-->В
И образуемые кластера :
(Шаг. №кластера)
1. 1.Е + ОМ значение кластера 2328
2. 1.
2. В + И 2732
3. 1. кластер поглощает вершину П, новый кластер Е+Ом+П 4667
2.
4. 1. поглощает вершину Л, новый кластер Е+Ом+П+Л 5161
2.
5. 1.
2. поглощает вершину О, новый кластер В + И + О 6588
6. 1 поглошает 2 и получается Л+Е+О+П+В+И+Ом 14946
1. Е--2328-->Ом
2. В--2732-->И
3. Е--4667-->П
4. Л--5161-->Ом
5. О--6588-->И
7. П--14946-->В
И образуемые кластера :
(Шаг. №кластера)
1. 1.Е + ОМ значение кластера 2328
2. 1.
2. В + И 2732
3. 1. кластер поглощает вершину П, новый кластер Е+Ом+П 4667
2.
4. 1. поглощает вершину Л, новый кластер Е+Ом+П+Л 5161
2.
5. 1.
2. поглощает вершину О, новый кластер В + И + О 6588
6. 1 поглошает 2 и получается Л+Е+О+П+В+И+Ом 14946
Надеюсь понятно..вот как я понял этот алгоритм вербально :
Цикл от i=0 до n-1
Цикл от j=0 до n-1
Если множество вершин ребра/кластераi при пересечении с множеством вершин ребра/кластераj образует не пустое множество
если значение ребра/кластераj >=значению ребра/кластераi
ТОГДА образуется кластер соединением множества вершин ребра/кластераj и множества вершин ребра/кластераi
ИНАЧЕ наше ребро и есть кластер.
Правильно ли я понял алгоритм?
Вот так его можно описать в коде..
//ribs это объект класса реализующего :
// QSet<int> - множество вершин ребра/кластера, возвращается путем вызова метода items()
// свойство value, которое возвращает вес ребра/кластера
//считать, что операции &, &= - пересечение
// += - слияние.
for(int i=0;i<ribs.size();++i)
for(int j=0;j<ribs.size();++j)
if (ribs.at(j)!=ribs.at(i))//не сравниваем сами с собой..
if ( (!(ribs.at(i)->items() & ribs.at(j)->items()).empty()))
//если пересечение не образует пустое множество
if (ribs.at(j)->value() >= ribs.at(i)->value())
//если значение j ребра/кластера меньше i
{
ribs.at(j)->items()+=ribs.at(i)->items();//соединяем j и i ребро/кластера
}
else
{
// ребро и есть кластер
}






 (С++ так С++, по-полной)
(С++ так С++, по-полной)