1. Пользуйтесь тегами кода. - [code] ... [/code] 2. Точно указывайте язык, название и версию компилятора (интерпретатора). 3. Название темы должно быть информативным. В описании темы указываем язык!!!
Вершины – объекты минимального остовного дерева группируются в кластеры. Выбираются два объекта, которым соответствует минимальное ребро minjdj, где j=1, n-1. Далее эти объекты стягиваются в один кластер (класс, таксон, страту) и процедура шага 2 повторяется до тех пор, пока на n-1 этапе группирования не будет сформирован один кластер, объединяющий все объекты. STOP.
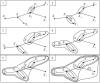
На рис. представлена последовательность группировки объектов в кластеры для заданного на рис.1 примера минимального остовного дерева. Порядок объединения объектов в кластеры отображён на рёбрах, которые связывают объединяемые объекты .Таким образом, первыми объединяются объекты X4 и Х5,которые в МОД связывает минимальное ребро d4 с весом 2. Вторыми объединяются объекты X2и X3, связанные ребром d2 с весом 3 , и так далее, пока на шестом этапе группирования ранее связанные объекты (X1,X2,X3,X4,X5,X6) не будут объединены с объектом X7 ребром с весом 7.
И так , перейдем к описанию алгоритма кластеризации на примере : Ребра МОД :
Цитата
(ИЗ--ВЕС-->В); 1. Е--2328-->Ом 2. В--2732-->И 3. Е--4667-->П 4. Л--5161-->Ом 5. О--6588-->И 7. П--14946-->В И образуемые кластера : (Шаг. №кластера) 1. 1.Е + ОМ значение кластера 2328 2. 1. 2. В + И 2732 3. 1. кластер поглощает вершину П, новый кластер Е+Ом+П 4667 2. 4. 1. поглощает вершину Л, новый кластер Е+Ом+П+Л 5161 2. 5. 1. 2. поглощает вершину О, новый кластер В + И + О 6588 6. 1 поглошает 2 и получается Л+Е+О+П+В+И+Ом 14946
Надеюсь понятно..вот как я понял этот алгоритм вербально : Цикл от i=0 до n-1 Цикл от j=0 до n-1 Если множество вершин ребра/кластераi при пересечении с множеством вершин ребра/кластераj образует не пустое множество если значение ребра/кластераj >=значению ребра/кластераi ТОГДА образуется кластер соединением множества вершин ребра/кластераj и множества вершин ребра/кластераi ИНАЧЕ наше ребро и есть кластер.
Правильно ли я понял алгоритм? Вот так его можно описать в коде..
//ribs это объект класса реализующего : // QSet<int> - множество вершин ребра/кластера, возвращается путем вызова метода items() // свойство value, которое возвращает вес ребра/кластера //считать, что операции &, &= - пересечение // += - слияние. for(int i=0;i<ribs.size();++i) for(int j=0;j<ribs.size();++j) if (ribs.at(j)!=ribs.at(i))//не сравниваем сами с собой.. if ( (!(ribs.at(i)->items() & ribs.at(j)->items()).empty())) //если пересечение не образует пустое множество if (ribs.at(j)->value() >= ribs.at(i)->value()) //если значение j ребра/кластера меньше i { ribs.at(j)->items()+=ribs.at(i)->items();//соединяем j и i ребро/кластера } else { // ребро и есть кластер }
Что-то ты нагромоздил кода, хотя просто я использую QtStl в своем проекте, там попроще с векторами и множествами, да и для представления ребер/кластеров я реализовал отдельный класс( просто выкладывать его сюда мало смысла - всеравно без Qt не получиться скомпилировать) А твой ответ не совсем ясен( честно скажу, в код не вникал). У него на Срезе 15 обременяются вершины Инская и лянгасово, т.к между ними мин. ребро на срезе 156 к этому ребру/кластеру добовляется вершина Орехово, т.к она связана с одной из вершин в предыдущем кластере(а именно - Инская) следующим мин. ребром с весом в 156..По тому же принципу и Егоршино на срезе 176 добавляется в тот же кластер, далее Омск на срезе 226, Пермь на срезе 239 (т.к все они имею связи через ребра МОД). На 334 срезе связывается Войновка и Екатеринбург, т.к они имею следующее мин. ребро из не использованных, и ни одна из этим вершин не имеется в предыдущих кластерах, поэтому они стают особняком на этом срезе, а после чего у них соединение на Перьми появляется и они объединяются в кластер..
А твои результаты я не понял. Может я плохо объясняю? Пожалуйста, спроси, что именно не понятно - я постараюсь объяснить более человеческим языком. Если надо, скину свои исходники.
Приведу всетаки полный код, может что яснее странет.. Сначала класс кластер/ребро : интерфейс :
#ifndef CLUSTER_H #define CLUSTER_H #include <QSet>// Qt'вые множества #include <QString>
class Cluster { private : int value_; QSet<int> items_; public : Cluster(); Cluster(Cluster & other);//конструктор копироавния Cluster(int item1 ,int item2, int nValue);//для ребра конструктор Cluster(int item1, int nValue);//для одной вершины const int& value()const {return value_; }//возвращает вес кластера/ребра void setValue(const int &newValue){value_=newValue;};//устанавливает вес QSet<int> &items();//возврашает вершины в кластере/ребре void append(Cluster * nClust);//"поглотить" другое ребро/кластер QString toString(QStringList * lst);//перевести номера вершин в их строковой эквивалент };
Cluster::Cluster(int item1 , int item2, int nValue) { value_=nValue; items_.insert(item1); items_.insert(item2); }
Cluster::Cluster(int item1 , int nValue) { value_=nValue; items_.insert(item1); }
void Cluster::append(Cluster * nClust) { QSetIterator <int> it (nClust->items()); while (it.hasNext())//Java-style итератор, очень удобно. Пока есть элементы в контейнере items_ << it.next();//забираем их из другого кластера. }
void Model::calculateNewClustersModel(QStandardItemModel * spanningMatrixModel) { clusters.clear();//очищаем вектор срезов. Представляет из себя QVector <QMap < int, QVector <Cluster* > > static bool *isNum = new bool; int rc = spanningMatrixModel->rowCount();//размер МОД int sM[rc][rc];//цисленный массив QVector <Cluster *> ribs;//вектор ребер.. for (int i=0;i<rc;++i) for (int j=0;j<rc;++j) sM[i][j]=spanningMatrixModel->item(i,j)->text().toInt(isNum,10); //перегоняет модель таблицы в численный массив for (int i=0;i<rc;++i) for (int j=i+1;j<rc;++j) if (sM[i][j]!=0) ribs.push_back(new Cluster(i,j,sM[i][j]));//собираем ребра qSort(ribs.begin(),ribs.end(),cmp);//сортируем их по возрастанию веса.
for(int i=0;i<ribs.size();++i) for(int j=0;j<ribs.size();++j) if (ribs.at(j)!=ribs.at(i))//не сравниваем сами с собой if ( (!(ribs.at(i)->items() & ribs.at(j)->items()).empty())) //если на пересечении не пустое множество if (ribs.at(j)->value() >= ribs.at(i)->value()) //и если ребро j имеет значение более ребра i { ribs.at(j)->items()+=ribs.at(i)->items();//поглатить ребро i qDebug() << "appended" <<ribs.at(j)->toString(&vHeaderData) << ribs.at(j)->value(); //Вывод информации о том, какой кластер поглатился и кем } else { qDebug() <<"single" <<ribs.at(i)->toString(&vHeaderData) << ribs.at(i)->value(); //Вывод информации о том, какое ребро является уже кластером } for(int i=0;i<ribs.size();++i) qDebug() << "2 " <<ribs.at(i)->toString(&vHeaderData) << ribs.at(i)->value() << " SIZE " << ribs.at(i)->items().size(); }
И вот вывод моего кода для "Вагонооборот" при 19 строках :
Что это значит?а вот что : SIZE - размер сформированного кластера, чилос перед SIZE - срез, на котором кластер сформирован, ну и соответственно его состав. Мой вопрос в том, что можно это как-либо оптимизировать?Допустим, что бы не проходил вершины, которые уже посчитал как еденичный кластер и т.д. Просто для параметра "Количество сортировочных путей" у меня считает не правильно кластера т.к там одинаковые ребра по весу.. Да к тому же , эта оптимизация мне нужная для того, что бы нормально отрисовывать дендрограмму ( как на сайте снизу), т.к я буду использовать "события" Qt(сигналы/слоты) что, кого поглотило и отрисовывать их по-порядку, а не после нахождения...