сыграем в Калах?

Эта игра меня давно занимает, причем с определенной точки зрения. Но сначала о том, что это за игра (не все, может, знакомы). Она очень древняя, пришла (как чуть ли не все игры) с Востока. Известна также под названием Ман-Кала, а также иногда пишут два "л": Каллах. Играют двое на специальной доске камнями. Доска имеет два ряда лунок (по шесть), а по бокам две большие лунки (именно они и называются "калах"). Доска ставится между двумя игроками. Ближайший ко мне ряд лунок - мой, другой - противника. Правый калах - мой, левый - противника.
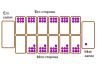
В начале игры во всех лунках (кроме калахов) лежит по шесть камней. Ход заключается в том, что игрок берет все камни из любой своей лунки (не из калаха) и раскладывает их по одному в направлении против часовой стрелки, начиная с ближайшей правой, и тут уже включая свой калах - но не калах противника, который пропускается.
Если при раскладывании последний камень попал в калах, то игрок ходит еще раз. Если последний камень попал в свою пустую лунку, а в противоположной лунке противника есть камни, то этот последний камень перекладывается в калах и все камни из противоположной лунки тоже перекладываются в калах игрока (если противоположная лунка была пуста, ничего не происходит).
Игра заканчивается либо когда в одном из калахов скопилось более половины всех камней (то есть больше 36), и тогда этот игрок выиграл, либо когда в лунках игрока кончились камни, и тогда он проиграл. Вот, кажется, и все правила. На рисунке изображено состояние после моего хода лункой №1. Сейчас снова мой ход.
Игра продавалась у нас, наверняка продается и сейчас. Играть интересно, ситуация на доске меняется иногда молниеносно, предсказать игру на пару ходов очень нелегко. Разумеется, есть и программные реализации (поройтесь в сети). В свое время все сотрудники нашего головного предприятия по производству ЭВМ были страстно увлечены ее электронной версией, проводились соревнования..
Понятно, что предсказание хода в данном случае трудно для человека, но не для машины - сбивает с толку необходимость постоянно вести подсчеты, но граф этой игры ветвится не так сильно, так как всякий раз есть не более шести возможных ходов.Вот именно эта особенность (малое количество ходов) и привлекла меня. Теперь расскажу о другом..
Когда-то давно я прочитал в книжке моего кумира Мартина Гарднера, как сделать машину для игры крестики-нолики. Ничего удивительного, если не сказать, что это было написано где-то в 60-е годы..
Машину предлагалось делать из.. спичечных коробков! Меня заинтересовал принцип. А принцип состоял в следующем.. По сути, это был метод кнута и пряника. Нужно было записывать все комбинации, возникающие в игре, зарисовывать их каждую на отдельном коробке. При игре 3х3 это возможно
. Но не только каждой комбинации соответствовал отдельный коробок, но и каждому возможному в ней ходу тоже. Перед процессом обучения "машины" в каждый коробок нужно было положить по три горошины. Потом нужно было несколько раз сыграть самому (с кем-нить) в эту игру, при каждом ходе фиксируя возникшие комбинации. В конце партии, когда результат (кто выиграл) уже ясен, нужно во все коробки, на которых обозначены ходы выигравшего игрока, должить по горошине. Из всех же тех, которые соответствуют ходам проигравшего игрока - наоборот, вынуть горошину. Я сейчас не ручаюсь за точность повторения алгоритма, но принцип тот.После достаточного количества сыгранных партий "машина" готова к игре - разумеется, вашими руками, но своим "мозгом". Игрок, играющий за машину должен всякий раз открывать все коробки, соответствующие текущему положению на доске, и выбрать из них тот, в котором больше всего гороха. Затем сделать тот ход, который обозначен на этом коробке.
Не правда ли, все просто? Если мое объяснение вам таковым не показалось, найдите книжку Гарднера
.Итак, я решил применить тот же принцип к Калаху. Это было давно, жутко давно - когда я впервые дорвался до персоналки. Тогда я это сделал на Бейсике. И ведь работало! Конечно, полный вариант мне был тогда не по зубам - не хватало ни памяти, ни производительности - но я извернулся. Придумал калах-3. Как вы, может, уже догадались, это вариант игры с тремя лунками, в каждой из которых в начале лежит 3 камня.
Да, не очень интересно.. Именно поэтому я помнил это и ждал момента, когда машины подрастут. Тогда я делал все на машине с памятью 512 КБ (аналог DEC Pro 350, кажется). Нынешние машины имеют памяти примерно на три порядка больше (а моя и вообще в 4000 раз). Так что я решил, что момент настал. И сделал все заново. Теперь на Паскале (с прицелом, чтоб выложить сюда
).Ну вот, теперь несколько слов о самой проге, да и хватит пока - устал долбить по клаве, однако..
Собсно, а что там говорить? Разберетесь.. Это Калах-4 (легко превращающийся в Калах-5,6 и т.д. заменой одной констаныт). Интерфейс крайне уродский, но не хочу доводить его до ума в текстовой версии. Во время игры можно только вводить номер лунки. Между играми можно кое-что еще (хелп по нажатии h). Советую переходить в режим картинки (буква p). Код непричесанный, невычищенный - короче, рабочий, не судите строго. Извиняюсь за отсутствие комментариев. Если будет интерес - снабжу.
Enjoy, как грится!
И - жду ваших коментариев.. улучшений.. и т.п.Да, забыл сказать.. Программа сама по себе страшно тупая - она ходит случайным образом. Чтоб ей поумнеть, нужен файл с накопленными данными. Файл у меня есть (для Калах-4), он весит почти 30 МБ - но вы можете сделать его и сами.
Самый интересный вопрос - оценка памяти, необходимой для обучения Калах-5 и 6. Я пока не соображу, как правильно оценить. Если верно, что каждый новый уровень требует примерно на 2.5-3 порядка большей памяти (как при переходе от 3 к 4), то для Калаха-5 потребуется больше 10 ГБ.. И такого количества операционки у меня пока нету.. Но мне кажется, что множитель не постоянен, он растет, но не спец по этим вопросам..
Итак - ваши соображения, господа?..
Старый вариант программы удален! Новый в посте №16