В общем, пишу сапер на Паскале, исключительно сам (впрочем, до этого момента), "от нечего делать", с псевдографикой и без использования приемов ООП.
Возникли два вопроса совершенно разного рода.
1) На поле есть такая ситуация (создавал в Paint, правя другое расположение мин, так что если есть какие-то несоответствия - извиняйте. Отдельное извинение за качество, случайно сохранил в .джпг, что мог - то подправил. Ну и английский
 ):
):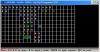
Допустим, все клетки поля не раскрыты. После нажатия клетки, которая "в фокусе" (выделенная зеленым), как должны открыться клетки? У меня варианта три:

Склоняюсь в верхнему справа, а что думаете вы?
2) Как можно гибко менять размеры окна (не в полноэкранном режиме)? Как я понял, с помощью процедуры TextMode гибкости не получить, я прав?
Спасибо
Сообщение отредактировано: volvo -